
0. 前言
Kaggle的房价预测比赛,数据集由Bart de Cock于2011年收集,涵盖了2006-2010年期间亚利桑那州埃姆斯市的房价。这个数据集是相当通用的,不会需要使用复杂模型架构。 它比哈里森和鲁宾菲尔德的波士顿房价数据集要大得多,也有更多的特征。
对应实践:https://github.com/silenceZheng66/deep_learning/blob/master/d2l/0x05.ipynb
1. 下载、缓存数据集
实现几个函数来方便下载数据,这些函数是用来下载、管理多个数据集的。
字典DATA_HUB将 数据集名称的字符串 映射到 数据集相关的二元组上, 这个二元组包含数据集的url和验证文件完整性的sha-1密钥。 所有这样的数据集都托管在地址为DATA_URL的站点上,这个链接是d2l的数据托管地址。1
2DATA_HUB = dict()
DATA_URL = 'http://d2l-data.s3-accelerate.amazonaws.com/'
实现一个download函数,当本地不存在数据时,下载数据集,当本地存在时,对本地数据集的sha-1密钥与数据托管地址中的比对,验证符合后使用本地数据集。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21def download(name, cache_dir=os.path.join('..', 'data')):
"""下载一个DATA_HUB中的文件,返回本地文件名"""
assert name in DATA_HUB, f"{name} 不存在于 {DATA_HUB}"
url, sha1_hash = DATA_HUB[name]
os.makedirs(cache_dir, exist_ok=True)
fname = os.path.join(cache_dir, url.split('/')[-1])
if os.path.exists(fname):
sha1 = hashlib.sha1()
with open(fname, 'rb') as f:
while True:
data = f.read(1048576)
if not data:
break
sha1.update(data)
if sha1.hexdigest() == sha1_hash:
return fname # 命中缓存
print(f'正在从{url}下载{fname}...')
r = requests.get(url, stream=True, verify=True)
with open(fname, 'wb') as f:
f.write(r.content)
return fname
实现两个实用函数: 一个将下载并解压缩文件, 另一个是将d2l书中使用的所有数据集从DATA_HUB下载到缓存目录中。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18def download_extract(name, folder=None):
"""下载并解压zip/tar文件"""
fname = download(name)
base_dir = os.path.dirname(fname)
data_dir, ext = os.path.splitext(fname)
if ext == '.zip':
fp = zipfile.ZipFile(fname, 'r')
elif ext in ('.tar', '.gz'):
fp = tarfile.open(fname, 'r')
else:
assert False, '只有zip/tar文件可以被解压缩'
fp.extractall(base_dir)
return os.path.join(base_dir, folder) if folder else data_dir
def download_all():
"""下载DATA_HUB中的所有文件"""
for name in DATA_HUB:
download(name)
2. 访问和读取数据集
竞赛数据分为训练集和测试集。 每条记录都包括房屋的属性值和属性。这些特征由各种数据类型组成。 例如,建筑年份由整数表示,屋顶类型由离散类别表示,其他特征由浮点数表示。
这就是现实让事情变得复杂的地方:例如,一些数据完全丢失了,缺失值被简单地标记为“NA”。
比赛最终要求我们预测测试集的价格。我们将划分训练集以创建验证集,但是在将预测结果上传到Kaggle之后,只能在官方测试集中评估模型。
数据集可以直接在Kaggle上下载,也可以用d2l的HUB下载。总之,最后得到all_features = pd.concat((train_data.iloc[:, 1:-1], test_data.iloc[:, 1:])) (去掉第一列是因为该数据集中第一列是ID属性,对模型和预测没有帮助;去掉train_data的最后一列,因为是标签)。
pd.concat() 可以沿着指定的轴将多个dataframe或者series拼接到一起,在这里就沿第一维(纵向)拼接到一起。
3. 数据预处理
建模之前先对数据进行预处理。
首先将所有缺失的值替换为相应特征的平均值。然后,为了将所有特征放在一个共同尺度上,将特征重新缩放到零均值和统一方差来标准化数据,通过以下公式:
替换后的特征具有零均值和统一的方差,也就是说缩放后的每个特征均值都为零且方差为实际方差, 即 $E\left[\frac{x-\mu}{\sigma}\right]=\frac{\mu-\mu}{\sigma}=0$ 和 $E\left[(x-\mu)^{2}\right]=\left(\sigma^{2}+\mu^{2}\right)-2 \mu^{2}+\mu^{2}=\sigma^{2}$(回忆$D(X)=E\left((X-E(X))^{2}\right)=E\left(X^{2}\right)-E^{2}(X)$)。
标准化数据有两个原因: 一是方便优化。二是在不明确特征相关性的情况下不让惩罚分配给某一特征的系数比分配给其他特征的系数更大。
1 | # 若无法获得测试数据,则可根据训练数据计算均值和标准差 |
这里有个值得注意的点就是筛选dtype != 'object'的元素,NumPy中数组存储为连续的内存块,通常具有单一数据类型(例如整数、浮点数或固定长度的字符串),然后内存中的位被解释为具有该数据类型的值。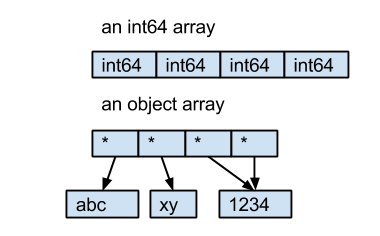
但用object类型创建数组是不同的,数组占用的内存此时由指向存储在内存中其他位置的 Python 对象的指针构成。
pandas的Dataframe使用了NumPy的object类型,Pandas存储字符串时正是使用这种类型,每一个object类型元素事实上是一个指针。
再处理离散值,使用独热编码替换它们,这样做将离散的字符串特征值也用数字表示出来。
例如,“MSZoning”包含值“RL”和“Rm”。 我们将创建两个新的指示器特征“MSZoning_RL”和“MSZoning_RM”,其值为0或1。 根据独热编码,如果“MSZoning”的原始值为“RL”, 则:“MSZoning_RL”为1,“MSZoning_RM”为0。 pandas软件包可以自动实现这一点。1
2
3# “Dummy_na=True”将“na”(缺失值)视为有效的特征值,并为其创建一个特征。
all_features = pd.get_dummies(all_features, dummy_na=True)
all_features.shape
由于我们对所有字符串类型的特征都应用了独热编码(该编码会使每一个值都形成一个特征),最终此转换会将特征的总数量从79个增加到331个。
最后通过values属性从pandas格式中提取NumPy格式,并将其转换为pytorch张量表示用于训练。1
2
3
4
5n_train = train_data.shape[0]
train_features = torch.tensor(all_features[:n_train].values, dtype=torch.float32)
test_features = torch.tensor(all_features[n_train:].values, dtype=torch.float32)
train_labels = torch.tensor(
train_data.SalePrice.values.reshape(-1, 1), dtype=torch.float32)
4. 训练
首先训练一个带有损失平方的线性模型作为基线(baseline)模型,让我们直观地知道最好的模型有超出简单的模型多少。
线性模型是最简单的深度学习模型(对比赛并无帮助),仅提供了一种查看数据中是否存在有意义的信息的功能。 如果它不能做得比随机猜测更好,那很可能存在数据处理错误。
对于房价的预测我们更多关心相对值, 而不是绝对值,即更关心相对误差 $\frac{y-\hat{y}}{y}$, 而不是绝对误差 $y-\hat{y}_{\text {。 }}$ 对一个房子价格的预测误差要与其本身的数量级进行比较,对千万级房子的价格预测出现10万左右的偏差时,比对百万级房子或价格更低的房子产生同样的误差更容易令人接受。
解决这个问题的一种方法是用价格预测的对数来衡量差异。事实上, 这也是比赛中官方用来评价提交质量的误差指标。即将 $\delta$ for $|\log y-\log \hat{y}| \leq \delta$ 转换为 $e^{-\delta} \leq \frac{\hat{y}}{y} \leq e^{\delta}$ 。这使得预测价格的对数与真实标签价格的对数之间出现以下均方根误差(Root Mean Square Error):
训练函数将借助Adam优化器,Adam优化器的主要吸引力在于它对初始学习率不那么敏感。
到这里,排除数据处理部分,基本上完成的工作就是:
1、提取了输入的特征张量
2、写一个获取单层网络的函数,输入特征输出标签
3、选定了对数RMSE的误差计算方法,并实现他
4、选定Adam优化器,实现了训练过程
以上代码详见实践对应仓库。
5. K折交叉验证
K折交叉验证有助于模型选择和超参数调整。 首先定义一个函数get_k_fold_data,在K折交叉验证过程中返回第 $i$ 折的数据。 具体地说,它选择第 $i$ 个切片作为验证数据,其余部分作为训练数据。 注意,这并不是处理数据的最有效方法,如果我们的数据集大得多,会有其他解决办法。 k_fold函数则负责在K折交叉验证中训练K次后,返回训练和验证误差的平均值。
总之,实现了K折交叉验证的部分,重新强调一下K折交叉验证解决的问题:在训练数据稀缺、无法构成足够的验证集的情况下,估计模型的误差。
6. 模型选择
到了这里,剩下的事情就是调参啦!1
2k, num_epochs, lr, weight_decay, batch_size = 5, 100, 5, 0, 64
train_l, valid_l = k_fold(k, train_features, train_labels, num_epochs, lr, weight_decay, batch_size)
可调整的超参数有:验证折数、训练周期、学习率、权重和批次大小。
目前为止,我们还没有开始真正的预测,只是用比赛中的训练数据,通过K折交叉验证来选择模型(调整超参数),使模型能够达到较好的误差,之后,我们再将模型应用于全部数据集,即包含测试数据集。
有时一组超参数的训练误差可能非常低,但K折交叉验证的误差要高得多,这表明模型过拟合了。
在训练过程中监控训练误差和验证误差,较少的过拟合可能表明现有数据可以支撑一个更强大的模型,较大的过拟合可能意味着可以通过正则化技术来获益。
7. 预测、提交
选定了模型之后,就可以将模型训练并应用于测试集进行预测,如果测试集上的预测与K折交叉验证过程中的预测相似,则可以将结果提交给Kaggle,判断预测标签与实际标签的差异。
提交后得到的score应该就是误差了,误差为0表示完全正确!
8. 小结
真实数据通常混合了不同的数据类型,需要进行预处理。
常用的预处理方法:将实值数据重新缩放为零均值和单位方法;用均值替换缺失值。
将类别特征转化为指标特征,可以使我们把这个特征当作一个独热向量来对待。
我们可以使用K折交叉验证来选择模型并调整超参数。
对数对于相对误差很有用。
TODO
改进模型来提高分数,应用多层、暂退法等技术。

