
前言
学深度学习也有一段时间了,想着同时也需要看一看机器学习的算法,对机器学习的基础有一个全面些的了解,过程中发现对个别机器学习库的了解不多,写个博客简单总结一下。
主要介绍的库有:
- pandas
- numpy
- scipy
- sklearn
NumPy
NumPy是使用Python进行科学计算的基础软件包。以纯数学的矩阵计算为基础。
核心功能包括: - 功能强大的N维数组对象。
- 精密广播功能函数。
- 集成 C/C+和Fortran 代码的工具。
- 强大的线性代数、傅立叶变换和随机数功能。
NumPy 最重要的一个特点是其 N 维数组对象 ndarray,它是一系列同类型数据的集合,以 0 下标为开始进行集合中元素的索引。ndarray 对象是用于存放同类型元素的多维数组。ndarray 中的每个元素在内存中都有相同存储大小的区域。
ndarray对象的内容可以通过索引或切片来访问和修改,与 Python 中 list 的切片操作一样。ndarray 数组可以基于 0 - n 的下标进行索引,切片对象可以通过内置的 slice 函数,并设置 start, stop 及 step 参数进行,从原数组中切割出一个新数组。
Pandas
Pandas是一个强大的分析结构化数据的工具集;它的使用基础是Numpy(提供高性能的矩阵运算);用于数据挖掘和数据分析,同时也提供数据清洗功能。
Series是一种类似于一维数组的对象,由一组数据(各种NumPy数据类型)以及一组与之相关的数据标签(即索引)组成。仅由一组数据也可产生简单的Series对象。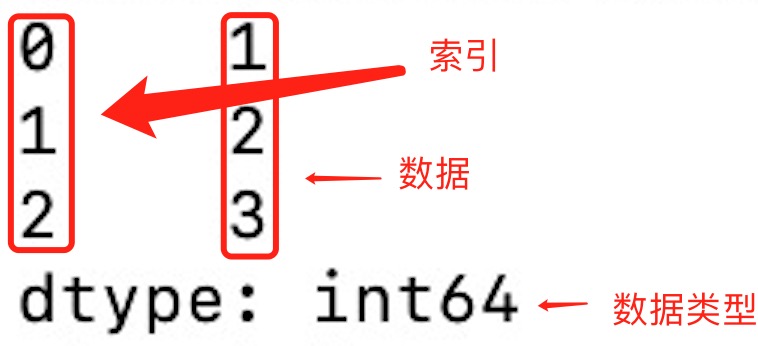
DataFrame是Pandas中核心的一个表格型的数据结构,包含有一组有序的列,每列可以是不同的值类型(数值、字符串、布尔型等),DataFrame即有行索引也有列索引,可以被看做是由Series组成的字典。
Pandas 适用于处理以下类型的数据:
- 与 SQL 或 Excel 表类似的,含异构列的表格数据;
- 有序和无序(非固定频率)的时间序列数据;
- 带行列标签的矩阵数据,包括同构或异构型数据;
- 任意其它形式的观测、统计数据集, 数据转入 Pandas 数据结构时不必事先标记。
利用Pandas做数据清洗也是一个非常常见的应用,例如空值、重复数据和错误数据的清洗。
SciPy
SciPy 是基于 Numpy 的科学计算库,用于数学、科学、工程学等领域,很多有一些高阶抽象和物理模型需要使用 SciPy。
NumPy 能够做一些基础的分析或变换,比如转置/逆矩阵/均值方差的计算等; SciPy则可以提供高阶的分析,比如拟合/回归/参数估计等。
SciPy被组织成覆盖不同科学计算领域的子包,如下:
| 子包 | 应用 |
|---|---|
| scipy.cluster | 矢量量化/Kmeans |
| scipy.constants | 物理和数学常数 |
| scipy.fftpack | 傅里叶变换 |
| scipy.integrate | 集成例程 |
| scipy.interpolate | 插值 |
| scipy.io | 数据输入和输出 |
| scipy.linalg | 线性代数例程 |
| scipy.ndimage | n维图像包 |
| scipy.odr | 正交距离回归 |
| scipy.optimize | 优化 |
| scipy.signal | 信号处理 |
| scipy.sparse | 稀疏矩阵 |
| scipy.spatial | 空间数据结构和算法 |
| scipy.special | 任何特殊的数学函数 |
| scipy.stats | 统计 |
Sklearn
全称Scikit-learn,Scikit-learn是一个开源的机器学习库,它支持有监督和无监督的学习。它还提供了用于模型拟合,数据预处理,模型选择和评估以及许多其他实用程序的各种工具。
支持机器学习的六大任务模块:分类(Classification)、回归(Regression)、聚类(Clustering)、降维、模型选择和预处理。
分类:识别某个对象属于哪个类别,常用的算法有:SVM(支持向量机)、nearest neighbors(最近邻)、random forest(随机森林),常见的应用有:垃圾邮件识别、图像识别。
回归:预测与对象相关联的连续值属性,常见的算法有:SVR(支持向量机)、 ridge regression(岭回归)、Lasso,常见的应用有:药物反应,预测股价。
聚类:将相似对象自动分组,常用的算法有:k-Means、 spectral clustering、mean-shift,常见的应用有:客户细分,分组实验结果。
降维:减少要考虑的随机变量的数量,常见的算法有:PCA(主成分分析)、feature selection(特征选择)、non-negative matrix factorization(非负矩阵分解),常见的应用有:可视化,提高效率。
模型选择:比较,验证,选择参数和模型,常用的模块有:grid search(网格搜索)、cross validation(交叉验证)、 metrics(度量)。它的目标是通过参数调整提高精度。
预处理:特征提取和归一化,常用的模块有:preprocessing,feature extraction,常见的应用有:把输入数据(如文本)转换为机器学习算法可用的数据。

