
前言
平时写代码、写博客总少不了与字符编码打交道,应该整理一下来做系统的了解。当然,我认为这种“目录”性质的博客不应写的过于深入,只要通过简短的文字介绍基本信息即可。
字符编码(Character encoding)
字符编码是把字符集中的字符编码为指定集合中某一对象,以便文本在计算机中存储和通过通信网络的传递。
对于软件开发中的场景来说,字符编码就是构建一个字符到数字的一一对应的映射关系。然而,在实际的应用中我们还需要解决字符间分隔问题。
在显示器上看见的文字、图片等信息在电脑里面其实并不是我们看见的样子,即使你知道所有信息都存储在硬盘里,把它拆开也看不见里面有任何东西,只有些盘片。假设,你用显微镜把盘片放大,会看见盘片表面凹凸不平,凸起的地方被磁化,凹的地方是没有被磁化;凸起的地方代表数字1,凹的地方代表数字0。硬盘只能用0和1来表示所有文字、图片等信息。
如上面引文中提到的,计算机只能对二进制数字进行读写,当它遇到00100001 00010001,它该如何知道这是一个双字节编码字符,又或是两个单字节编码的字符呢?通常解决方案要么就是规定好每个字长度(例如所有文字都是2 bytes,不够的前面用0补齐),要么就是在用0和1表示的时候,不仅需要表示出数字编码,还要暗示给计算机接下来多少个连续byte构成一个字。
不同的字符编码(有时也称为字符集)的区别主要在于两点:可以表示的字符范围 和 编码方式。几种常见的中文编码之间兼容性如下图所示,兼容是指映射间的包含关系:
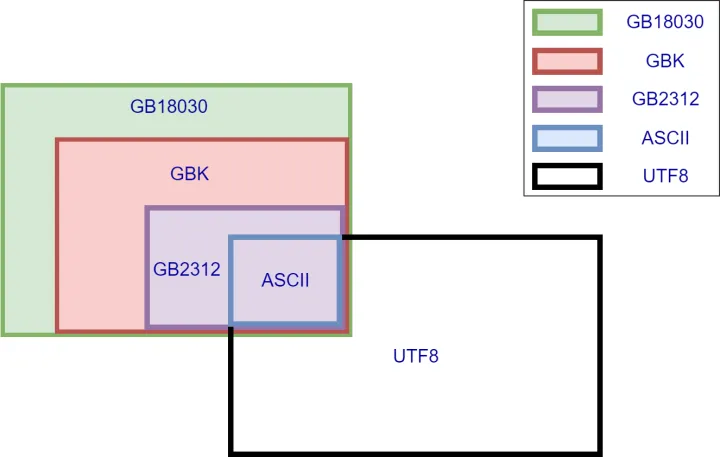
ASCII
ASCII 字符集和 ASCII 码( ASCII 是 American Standard Code for Information Interchange 的缩写)可能是我们最先接触到的英文字符集及其编码,它同时也被国际标准化组织( International Organization for Standardization, ISO )批准为国际标准。
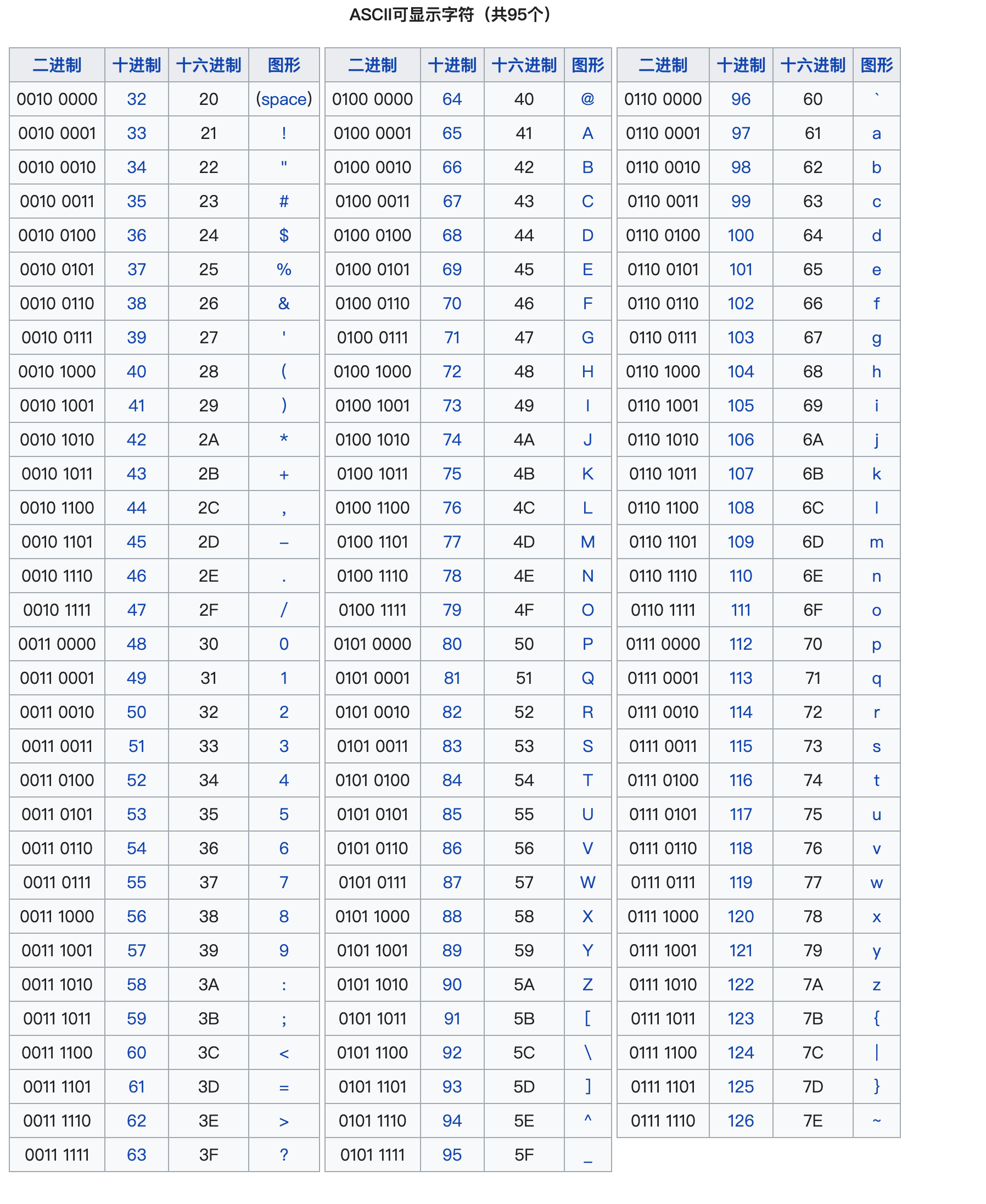
基本的 ASCII 字符集共有 128 个字符,其中有 96 个可打印字符(可打印和可显示仍有一个字符的区别),包括常用的字母、数字、标点符号等,另外还有 32 个控制字符。标准 ASCII 码使用 7 个二进位对字符进行编码,对应的 ISO 标准为 ISO646 标准。
由于标准 ASCII 字符集字符数目有限,在实际应用中往往无法满足要求。为此,国际标准化组织又制定了 ISO2022 标准,它规定了在保持与 ISO646 兼容的前提下将 ASCII 字符集扩充为 8 位代码的统一方法。 ISO 陆续制定了一批适用于不同地区的扩充 ASCII 字符集,每种扩充 ASCII 字符集分别可以扩充 128 个字符,这些扩充字符的编码均为高位为 1 的 8 位代码(即十进制数 128~255 ),称为扩展 ASCII 码。
字母和数字的 ASCII 码的记忆是非常简单的。我们只要记住了一个字母或数字的 ASCII 码(例如记住 A 为 65 , 0 的 ASCII 码为 48 ),知道相应的大小写字母之间差 32 ,就可以推算出其余字母、数字的 ASCII 码。
ASCII编码几乎被世界上所有编码所兼容(UTF-16和UTF-32是个例外),因此如果一个文本文档里面的内容全都由ASCII里面的字母或符号构成,那么不管你如何展示该文档的内容,都不可能出现乱码的情况。
ANSI
准确说,并不存在哪种具体的编码方式叫做ANSI,它只是一个Windows操作系统上的别称而已。在中文简体Windows操作系统上,ANSI就是GBK;在泰语操作系统上,ANSI就是TIS-620(一种泰语编码);在韩语操作系统上,ANSI就是EUC-KR(一种韩语编码)。
为了扩充ASCII编码,以用于显示本国的语言,不同的国家和地区制定了不同的标准,由此产生了 GB2312, BIG5, JIS 等各自的编码标准。这些使用 2 个字节来代表一个字符的各种汉字延伸编码方式,称为 ANSI 编码,又称为”MBCS(Muilti-Bytes Character Set,多字节字符集)”。 不同 ANSI 编码之间互不兼容,当信息在国际间交流时,无法将属于两种语言的文字,存储在同一段 ANSI 编码的文本中。一个很大的缺点是,同一个编码值,在不同的编码体系里代表着不同的字。这样就容易造成混乱。于是催生了Unicode。
其中每个语言下的ANSI编码,都有一套一对一的编码转换器,Unicode变成所有编码转换的中间介质。所有的编码都有一个转换器可以转换到Unicode,而Unicode也可以转换到其他所有的编码。
GBK、GB2312
GB即国标,为了满足国内在计算机中使用汉字的需要,中国国家标准总局发布了一系列的汉字字符集国家标准编码,统称为GB码,或国标码。其中最有影响的是于1980年发布的《信息交换用汉字编码字符集 基本集》,标准号为GB 2312-1980,因其使用非常普遍,也常被通称为国标码。GB2312编码通行于我国内地;新加坡等地也采用此编码。几乎所有的中文系统和国际化的软件都支持GB2312。
GBK和GB2312都是双字节编码。
GB2312是一个简体中文字符集,由6763个常用汉字和682个全角的非汉字字符组成。其中汉字根据使用的频率分为两级。一级汉字3755个,二级汉字3008个。
GB2312的出现,基本满足了汉字的计算机处理需要,但对于人名、古汉语等方面出现的罕用字,GB2312不能处理,这导致了后来GBK的出现。经过GBK编码后,可以表示的汉字达到了20902个,另有984个汉语标点符号、部首等。
当GBK仍然无法满足使用的需要时,就产生了GB18030,这时2bytes已经不能满足使用的需要(2bytes最多只有65536种组合,然而为了和ASCII兼容,最高位不能为0就已经直接淘汰了一半的组合,只剩下3万多种组合无法满足全部汉字要求),因此GB18030多出来的汉字使用4bytes编码。
Unicode
Unicode是为了解决传统的字符编码方案的局限而产生的,它为每种语言中的每个字符设定了统一并且唯一的二进制编码,以满足跨语言、跨平台进行文本转换、处理的要求。Universal Multiple-Octet Coded Character Set,简称为UCS。UCS-2,即2字节编码字符集,UCS-4则是4字节编码字符集。
但是,Unicode仅仅是一本很厚的字典,规定了符合对应的二进制代码,至于这个二进制代码如何存储则没有任何规定。也就是说,其中一个字符可能只对应7位二进制数,而另一个字符则对应27位二进制数。如果按照统一用4字节存储字符编码的话,无疑会造成极大的资源浪费(对磁盘、对网络都是)。为了解决这一问题,产生了许多Unicode的实现方式,如utf-8、utf-16等等。
UTF-8(8-bit Unicode Transformation Format)
UTF-8解决字符间分隔的方式是数二进制中最高位连续1的个数来决定这个字是几字节编码。0开头的属于单字节,和ASCII码重合,做到了兼容。
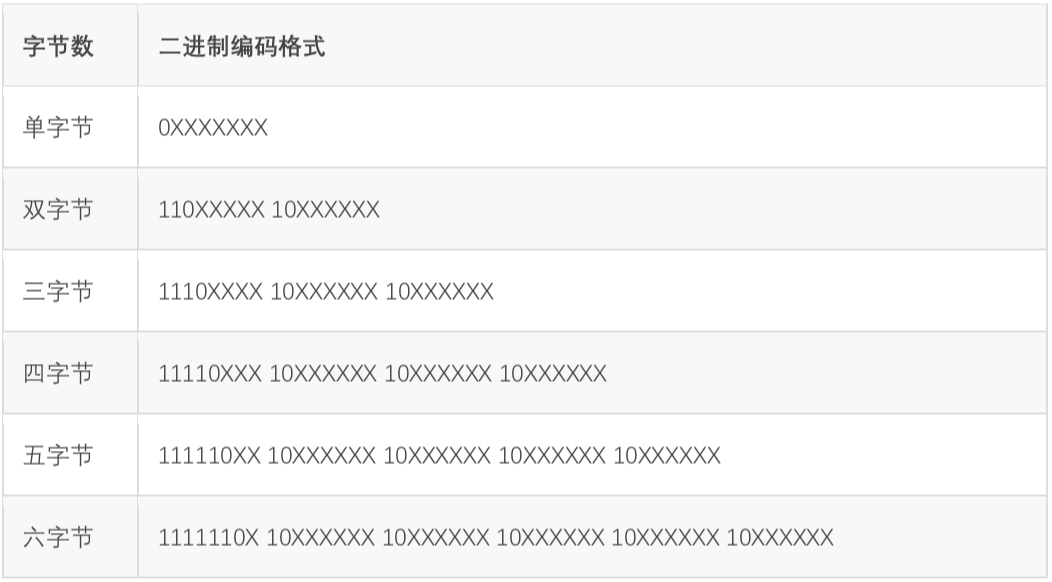
从这种表示方式也可以很显然地看出来,UTF-8 和 GBK 没有任何关系,除了都兼容ASCII以外。这也是文件乱码的主要原因之一。
UTF-8中,中文占 3 个字节,其他数字、英文、符号占一个字节。但 emoji 符号占 4 个字节,一些较复杂的文字、繁体字也是 4 个字节。
我们可能会注意到MySQL中有两套UTF-8的实现,分别是utf8和utf8mb4,它们的区别如下:
utf8:只支持1至3个字节。utf8mb4:完整实现,最多支持4个字节表示字符。
因此,如果需要存储emoji类型的数据或者一些比较复杂的文字、繁体字到MySQL的话,数据库的编码一定要指定为utf8mb4。
关于更多Unicode编码方式的内容
其实我认为常用的字符编码除了utf-8,还有utf-16。汉字的Unicode范围在[0x4E00, 0x9FA5],这里是码点的范围,也就是U+4E00 到 U+9FA5。这个范围是CJK Unified Ideographs。
更多内容可以参考[7]、[8]。
参考
[1]https://baike.baidu.com/item/%E5%AD%97%E7%AC%A6%E7%BC%96%E7%A0%81/8446880
[2]https://www.cnblogs.com/zhanghengscnc/p/7664120.html
[3]https://zhuanlan.zhihu.com/p/46216008
[4]https://baike.baidu.com/item/%E7%BB%9F%E4%B8%80%E7%A0%81/2985798
[5]https://www.cnblogs.com/crazylqy/p/10184291.html
[6]https://javaguide.cn/database/character-set.html
[7]https://cloud.tencent.com/developer/article/1341908
[8]https://www.cnblogs.com/benbenalin/p/6921553.html
后记
首发于 silencezheng.top,转载请注明出处。

