
前言
图卷积学习记录,同时也涉及离散拉普拉斯算子内容,可能对视觉方向有帮助。
相关内容:卷积、傅立叶变换、拉普拉斯算子、狄利克雷能量、图卷积
传统卷积
传统的卷积主要应用于Euclidean Structure的数据上(排列很整齐、Grid形式的),如图像、语句等,主要是因为欧式结构数据能够保证卷积的性质,即平移不变性,而Non-Euclidean无法保证平移不变性,通俗理解就是在拓扑图中每个顶点的相邻顶点数目都可能不同,那么当然无法用一个同样尺寸的卷积核来进行卷积运算。
推广卷积到图
卷积定理指出,函数卷积的傅里叶变换是函数傅里叶变换的乘积。即一个域中的卷积对应于另一个域中的乘积, 例如时域中的卷积对应于频域中的乘积。
其中 $\mathcal{F}(f)$ 表示 $f$ 的傅里叶变换。下面这种形式也成立:
借由傅里叶逆变换 $\mathcal{F}^{-1}$, 也可以写成:
注意以上的写法只对特定形式定义的变换正确,变换可能由其它方式正规化,使得上面的关系式中出现其它的常数因子。
这一定理对拉普拉斯变换、双边拉普拉斯变换、Z变换、梅林变换和Hartley变换等各种傅里叶变换的变体同样成立。
利用卷积定理可以简化卷积的运算量。对于长度为 $n$ 的序列,按照卷积的定义进行计算,需要做 $2 n-1$ 组对位乘法,其计算复杂度为 $\mathcal{O}\left(n^2\right)$;而利用傅里叶变换将序列变换到频域上后,只需要一组对位乘法,利用傅里叶变换的快速算法之后,总的计算复杂度为 $\mathcal{O}(n \log n)$ 。这一结果可以在快速乘法计算中得到应用。
傅里叶变换又可以通过谱图理论推广到图上进行变换。
谱图理论是图论与线性代数相结合的产物,它通过分析图的某些矩阵的特征值与特征向量而研究图的性质。拉普拉斯矩阵是谱图理论中的核心与基本概念,在机器学习与深度学习中有重要的应用。包括但不仅限于:流形学习数据降维算法中的拉普拉斯特征映射、局部保持投影,无监督学习中的谱聚类算法,半监督学习中基于图的算法,以及目前炙手可热的图神经网络等。还有在图像处理、计算机图形学以及其他工程领域应用广泛的图切割问题。理解拉普拉斯矩阵的定义与性质是掌握这些算法的基础。
所以,Convolution —— Fourier —— Spectral Graph,卷积通过傅里叶变换和图(频谱域)发生了联系。
从整个的研究进程来看,首先是研究GSP(Graph Signal Processing)的学者提出了Graph上的Fourier Transformation,进而定义了Graph的Convolution,最后与深度学习结合起来,发展出来GCN。
图傅立叶变换的实施
关于时域和频域,我在高斯滤波和双边滤波一文中已有一些介绍。
此处需要强调的一点是傅里叶级数是向量,一般描述向量的时候,都有对应的基,即在某组基下的坐标表示构成了向量。默认是单位基时,则不显式提到。频域下,某个曲线是表示成了关于正弦函数正交基下的傅里叶级数向量。而在时域下,某个曲线是表示成了关于时间的周期函数。不管时域还是频域,其实反映的都是同一个曲线,只是一个是用函数的观点,一个是用向量的观点。
图上的傅里叶变换是通过下述联系实施的:
- 图拉普拉斯算子, Laplacian Operator —- Graph Laplacian Matrix。
- 图拉普拉斯的谱分解,Graph Laplacian Matrix —- Spectral Decomposition。
- 图上狄利克雷能量最小的基, Dirichlet Energy —- Orthonormal Basis —- Spectral Decomposition —- Eigenvectors
- 傅里叶变换,Fourier —- Fourier Basis —- Laplacian eigenfunctions
根据4,可以证明,Fourier basis = Laplacian eigenfunctions,即傅立叶级数的基(和频率一一对应)是拉普拉斯算子的特征函数 (满足特征方程)。根据1,在图上,拉普拉斯算子为拉普拉斯矩阵。根据2,拉普拉斯矩阵的谱分解得到的特征向量(和特征值一一对应)类比特征函数。因此,传统傅里叶变换在图的拓展就是将正弦函数基替换换成图拉普拉斯矩阵的特征向量,正弦函数与频率一一对应,特征向量与特征值一一对应。而根据3,这一替换的根源意义在于,图拉普拉斯矩阵的特征向量作为一组基的话,这组基是图上狄利克雷能量最小的基。
Laplacian Operator(拉普拉斯算子)和Laplacian eigenfunctions(拉普拉斯特征函数)是在图论和图信号处理中密切相关的概念。
Laplacian Operator:
在图论中,Laplacian Operator是用来描述图的拓扑结构和节点之间连接关系的算子。对于一个无向图G,Laplacian Operator通常定义为度矩阵(Degree Matrix)D和邻接矩阵(Adjacency Matrix)A之间的差,即L = D - A。其中,度矩阵D是一个对角矩阵,其对角线元素是每个节点的度数(与该节点相连接的边的数量),邻接矩阵A描述了节点之间的连接关系。
Laplacian Operator有多种形式,常见的有度标准化Laplacian、随机游走标准化Laplacian等,不同的形式在不同的图信号处理任务中有不同的应用。Laplacian eigenfunctions:
Laplacian eigenfunctions是指Laplacian Operator对应的特征函数,也称为拉普拉斯特征向量。Laplacian Operator的特征函数是在图上定义的一组正交函数,它们描述了图的振动模式和频率。对于图的Laplacian Operator L,它可以进行谱分解,得到一组特征向量(Laplacian eigenfunctions)和对应的特征值(Laplacian eigenvalues)。这些特征向量在图信号处理中具有重要的意义,它们构成了一个基,可以用于将图信号从原始的节点空间转换到频域空间,类似于傅里叶变换中的基函数。
Laplacian eigenfunctions对应的特征值可以用来表示图的结构和节点之间的连接关系,不同的特征值对应不同的频率,反映了图的振动特性。在图信号处理任务中,Laplacian eigenfunctions常常被用作图嵌入、图卷积神经网络(GCN)等方法的基础,以便有效地学习图的特征和结构。
图拉普拉斯算子
先讨论常规连续拉普拉斯算子,然后通过有限差分法在离散网格上近似计算拉普拉斯算子,对其进行离散化。
有限差分法是将导数或微分算子替换为差分的形式,从而将微分方程转化为差分方程。
差分方程是一种数学方程,用于描述离散点之间的关系,通常在数值计算和离散模型中使用。与微分方程类似,差分方程是在离散时间或空间上建立函数之间的关系,而不是连续变量的关系。
最后,我们推广到图结构上。
拉普拉斯算子(Laplacian Operator)
拉普拉斯算子的严格数学定义:多元函数$f(x_1,…,x_n)$的拉普拉斯算子是所有自变量的非混合二阶偏导数之和。
基于定义,所有的__拉普拉斯算子都是其一个特例,或是某种情况下(比如离散情况下)的一种近似。很多时候我们之只能近似计算导数值,称为数值微分。
数值微分是一种通过数值计算来近似计算函数的导数的方法。它在数值分析和科学计算中经常用于解决无法通过解析方法求得导数的问题,或者用于验证解析导数的结果。
数值微分的基本思想是利用函数在某一点附近的函数值来近似计算该点的导数。常见的数值微分方法包括:
中心差分法: 中心差分法使用函数在当前点的前后两个邻近点的函数值来近似计算导数。它的计算公式如下:
这里,$h$ 是一个小的正数,代表点的间隔。
前向差分法: 前向差分法使用函数在当前点和该点之后的一个邻近点的函数值来近似计算导数。它的计算公式如下:
后向差分法: 后向差分法使用函数在当前点和该点之前的一个邻近点的函数值来近似计算导数。它的计算公式如下:
数值微分方法的精度取决于间隔$h$的大小,过大的$h$可能引入较大的近似误差,而过小的$h$可能引入舍入误差。选择合适的$h$值是确保数值微分结果精度的关键。
对于二阶导数,则有:
下面考虑多元函数的偏导数。对于二元函数$f(x,y)$,其拉普拉斯算子可以用下面的公式近似计算:
离散拉普拉斯算子
图像和图结构都是离散数据,其拉普拉斯算子必然要进行离散化。如果上面的二元函数进行离散化,对自变量的一系列点处的函数值进行采样,得到下面一系列点处的函数值,构成一个矩阵。
在这里 $x$ 为水平方向, $y$ 为垂直方向。为了简化, 假设 $x$ 和 $y$ 的增量(步长)全为 $1$ , 即:
则点 $\left(x_i, y_j\right)$ 处的拉普拉斯算子可以用下面的公式近似计算:
这是一个非常优美的结果, 它就是 $\left(x_i, y_j\right)$ 的 4 个相邻点处的函数值之和与 $\left(x_i, y_j\right)$ 点处的函数值乘以 4 后的差值。如下图所示:
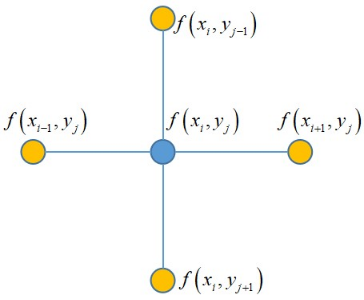
基于这种离散表示,拉普拉斯算子的计算公式可以写成如下形式:
其中 $N(i, j)$ 是 $\left(x_i, y_j\right)$ 邻居节点的集合。
这也给我们一种形象的结论:二维网格(离散二元函数)上计算某点的拉普拉斯算子就是计算上下左右四个自由度上的“变化和”。
PS:变化和是笔者的个人理解,也有人说是“微小变化后获得的增益”。另外,对于二维网格,也可以拓展出八个自由度的拉普拉斯算子。
图上的拉普拉斯算子
在图中,顶点的连接关系是任意的,这意味着顶点的邻居节点数量不固定。将拉普拉斯算子推广到图上,如果将图的顶点处的值看作是函数值,则在顶点$i$处的拉普拉斯算子为:
其中 $N_i$ 是顶点 $i$ 的所有邻居顶点的集合。这里我们调换了 $f_i$ 和 $f_j$ 的位置, 和之前的拉普拉斯算子相比, 相当于多了一个负号。由于图的边可以带有权重, 我们可以在上面的计算公式中加上权重:
如果 $j$ 不是 $i$ 的邻居, 则 $w_{i j}=0$ 。因此上面的式子也可以写成如下形式:
这里的 $d_i$ 是顶点 $i$ 的加权度,$w_i$ 是邻接矩阵的第 $i$ 行, $f$ 是所有顶点的值构成的列向量, $w_i f$ 是二者的内积。对于图的所有顶点, 有
上式的全称是:图拉普拉斯算子作用在由图节点信息构成的向量$f$上得到的结果等于图拉普拉斯矩阵和向量$f$的点积。
这也说明,在图上,拉普拉斯算子等于拉普拉斯矩阵。
图拉普拉斯矩阵(Laplacian Matrix)
由此,我们推出了无向图上定义拉普拉斯矩阵的一种方式:
其中,$L$是图拉普拉斯矩阵,$D$是加权度矩阵(Weighted Degree Matrix),$A$是邻接矩阵(Adjacency Matrix)。
由于$D$ 和 $A$都是对称矩阵,则无向图的拉普拉斯矩阵也是对称矩阵,它实际上代表了图的二阶导数。
显然无向图拉普拉斯矩阵每一行元素之和都为 0 。下面介绍拉普拉斯矩阵的若干重要性质(省略证明):
1、对任意向量 $\mathbf{f} \in \mathbb{R}^n$ 有:
2、拉普拉斯矩阵是对称半正定矩阵;
3、拉普拉斯矩阵的最小特征值为 0 ,其对应的特征向量为常向量 1 ,即所有分量为 1 ;
4、拉普拉斯矩阵有 $n$ 个非负实数特征值,并且满足:
5(结论)、假设 $G$ 是一个有非负权重的无向图,其拉普拉斯矩阵 $L$ 的特征值0的重数 $k$ 等于图的联通分量的个数$A_1, \ldots, A_k$。特征值0的特征空间由这些联通分量所对应的特征向量$\mathbf{1}_{A_1}, \ldots, \mathbf{1}_{A_k}$所张成。
对于结论5,举一个例子进行说明:
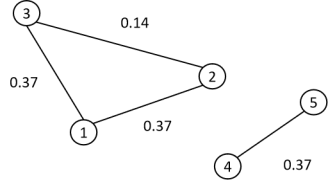
上图有两个联通子图,其邻接矩阵为:
其加权度矩阵为:
拉普拉斯矩阵为:
它由如下两个子矩阵构成:
每个子矩阵对应于图的一个联通分量。0 是每个子矩阵的 1 重特征值,由于有两个联通分量,因此 0 是整个图的拉普拉斯矩阵的 2 重特征值。两个线性无关的特征向量为:
归一化拉普拉斯矩阵(Normalized Laplacian Matrix)
图拉普拉斯矩阵有两种形式的归一化。
第一种称为对称归一化,定义为:
这里 $D^{1 / 2}$ 是 $D$ 的所有元素计算正平方根得到的矩阵。位置为 $(i . j), i \neq j$ 的元素为将未归一化拉普拉斯矩阵对应位置处的元素 $l_{i j}$ 除以 $\sqrt{d_{i i} d_{j j}}$ 后形成的,主对角线上的元素为 1 :
由于 $D^{1 / 2}$ 和 $L$ 都是对称矩阵, 因此 $L_{sym}$ 也是对称矩阵。如果图是联通的,则 $D$ 和 $D^{1 / 2}$ 都是可逆的对角矩阵,其逆矩阵分别为其主对角线元素的逆。
第二种称为随机漫步归一化,定义为:
其位置为 $(i, j), i \neq j$ 的元素为将未归一化拉普拉斯矩阵对应位置处的元素 $l_{i j}$ 除以 $d_{i i}$ 后形成的,主对角线元素也为 1:
下面介绍这两种归一化矩阵的若干重要性质:
1、对任意向量 $\mathbf{f} \in \mathbb{R}^n$ 有:
2、$\lambda$ 是矩阵 $L_{rw}$ 的特征值,$\mu$ 是特征向量, 当且仅当 $\lambda$ 是 $L_{sym}$ 的特征值且其特征向量为 $w=D^{1 / 2} \mu$。
3、$\mu$ 是矩阵 $L_{rw}$ 的特征值,$\mu$ 是对应的特征向量,当且仅当 $\lambda$ 和 $\mu$ 是广义特征值问题 $L u=\lambda D u$ 的解。
4、0 是矩阵 $L_{rw}$ 的特征值,其对应的特征向量为常向量 1 ,即所有分量为 1。 0 是矩阵 $L_{sym}$ 的特征值,其对应的特征向量为 $D^{1 / 2} 1$ 。
5、矩阵 $L_{sym}$ 和 $L_{rw}$ 是半正定矩阵,有 $n$ 个非负实数特征值, 并且满足:
6(结论)、和未归一化的拉普拉斯矩阵类似,假设 $G$ 是一个有非负权重的无向图,其归一化拉普拉斯矩阵 $L_{rw}$ 和 $L_{sym}$ 的特征值0的重数 $k$ 等于图的联通分量的个数 $A_1, \ldots, A_k$ 。
对于矩阵 $L_{rw}$,特征值0的特征空间由这些联通分量所对应的向量 $1_{A_1}, \ldots, 1_{A_k}$ 所张成。 $1_{A_i}$ 的定义与未归一化拉普拉斯矩阵0特征值的特征向量相同。
对于矩阵 $L_{sym}$, 特征值O的特征空间由这些联通分量所对应的向量 $\mathbf{D}^{1 / 2} \mathbf{1}_{A_1}, \ldots, \mathbf{D}^{1 / 2} \mathbf{1}_{A_k}$ 所张成。
拉普拉斯矩阵的谱分解(Spectral Decomposition)
在矩阵范围内,不考虑过于复杂的数学概念,谱分解又称为特征值分解,只有方阵才能进行谱分解。
特征向量(Eigenvectors):一个矩阵的特征向量是指一个非零向量,其在经过矩阵变换后只发生了伸缩而没有改变方向,只相差了一个常数倍数。换句话说,矩阵乘以特征向量后,相当于对该向量进行了一个比例的拉伸。
特征值(Eigenvalues):特征值是对应于特征向量的标量,它表示了在特征向量进行矩阵变换后的伸缩倍数。一个矩阵可以有多个特征向量和对应的特征值。
对于一个方阵 $A$,谱分解的基本思想是将它表示为特征向量矩阵 $P$ 与对角特征值矩阵 $Λ$ 相乘的形式,即 $A = P Λ P^{-1} $。如果 $A$ 是对称矩阵,则 $P$ 是正交矩阵,则原式也可写作 $A = P Λ P^T$。
由于拉普拉斯矩阵是对称半正定的,我们可以得到以下性质:
1、一定有$n$个线性无关的特征向量(对称)。
2、矩阵的特征值一定非负(半正定)。
3、矩阵的特征向量相互正交,即所有特征向量构成的矩阵为正交矩阵(对称)。
所以,拉普拉斯矩阵 $L$ 的谱分解也可以写成 $P Λ P^T$ 的形式,如下所示:
$\Phi=\left(\phi_1, \phi_2, \ldots, \phi_n\right) \in \mathbb{R}^{\mathrm{n} \times n}$ 是正交矩阵,其列向量为单位特征向量。
$\Lambda=\operatorname{diag}\left(\lambda_1, \ldots, \lambda_n\right)$ 是由对应特征值构成的对角矩阵。
狄利克雷能量(Dirichlet Energy)
狄利克雷能量衡量了函数的平滑性(Smoothness),越小说明函数越平滑。狄利克雷能量定义为:
其中$f$ 是函数,$\Delta$ 是拉普拉斯算子。整个公式在图结构上的含义是,计算函数$\boldsymbol{f}$在图的节点上的变化程度,其中变化程度通过将函数$\boldsymbol{f}$映射到拉普拉斯矩阵的空间($\boldsymbol{\Delta} \boldsymbol{f}$),并计算映射后的向量与原向量的内积来衡量。
在图论中,狄利克雷能量越小表示图中节点的函数在空间中变化越平滑,节点之间的连接或关系越紧密。这可以用于量化图中的平滑性和连通性。
那么,狄利克雷能量最小化问题对推广图傅立叶变换有什么帮助呢?
图傅立叶变换是将一个定义在图的节点上的函数映射到频谱域,类似于信号处理中的傅立叶变换。在连续信号的情况下,傅立叶变换将信号分解为不同频率的正弦和余弦函数。类似地,在图上,图傅立叶变换将一个函数分解为图中的基函数,这些基函数由狄利克雷能量最小化问题得到。
我们的目标是寻找图上狄利克雷能量最小的一组单位正交基(每个基都可以看成函数)。 巧合的是,这样的正交基正好就是对拉普拉斯矩阵 $L$ 进行谱分解得到的单位特征向量 $\phi_1, \ldots, \phi_n$ 。 这对我们从传统傅里叶变换推广到图上傅里叶变换时进行的类比和替换提供了理论解释。
图傅立叶变换(Graph Fourier Transformation)
简单回顾傅立叶变换,然后推广到图。
傅立叶变换(Fourier Transformation)
傅里叶变换于将一个函数从时间(或空间)域转换到频率域,以便分析其频率特性。傅里叶变换可以将一个信号分解成不同频率的成分,从而揭示出信号的频谱信息。
傅里叶变换的公式如下:
对于连续信号:
对于离散信号:
其中,$ F(\omega) $ 或 $ F(k)$ 是信号在频率域的表示,$ f(t) $ 或 $ f(n) $ 是信号在时间(或空间)域的表示,$ \omega $ 是角频率,$ j $ 是虚数单位, $ t $ 或 $ n $ 是时间(或空间)的变量。
$F(\omega)$ 就是傅里叶变换,得到的就是频域图,它在 $\omega_0$ 的值 $F(\omega_0)$ 表示 $f(x)$ 在 $\omega_0$ 频率对应的正交基上的系数。
下面两者称为傅里叶变换对, 可以相互转换:
另外,$e^{-j\omega t}$ 是傅立叶基函数之一,也被称为复指数函数。傅立叶变换可以将一个函数从时域转换到频域,它将一个函数表示为不同频率的正弦和余弦函数的叠加。$e^{-j\omega t}$ 就是这些正弦和余弦函数的复数形式,参照$e^{jx} = \cos(x) + j \sin(x)$。
傅立叶基函数(Fourier Basis Functions)
傅立叶基函数(Fourier Basis Functions)是一组正交函数,用于展开和表示信号在频率域的成分。在傅立叶变换中,原始信号可以被分解为各种频率的正弦和余弦函数的线性组合,而这些正弦和余弦函数就构成了傅立叶基函数。
傅立叶基函数的具体形式取决于是连续信号还是离散信号。对于连续信号,傅立叶基函数是正弦和余弦函数,表达式如下:
其中,$k$ 为频率索引,$f$ 为信号的基本频率,$T$ 为信号的周期。
对于离散信号,傅立叶基函数是复指数函数,表达式如下:
其中,$k$ 为频率索引,$N$ 为信号的样本点数。
傅立叶基函数构成了频率域的正交基,意味着不同频率的基函数之间彼此正交。通过将信号在傅立叶基函数上的投影,我们可以得到信号在不同频率上的分量,从而实现频域分析。
傅立叶基函数是傅立叶变换的核心概念,它们的线性组合可以用来表示任何信号。
图傅立叶变换
首先,在图上,拉普拉斯算子等于拉普拉斯矩阵。复指数函数$e^{-j\omega t}$,即傅立叶变换的基函数,可以被证明是图上拉普拉斯算子的一个特征函数。
在图上作类比,令变量为 $x$,令频率为 $\mathrm{k}$ (注意与角频率的区别), $\phi_{\mathrm{k}}$ 为图拉普拉斯算子 $L$ 的特征向量(满足 $L \phi_k=\lambda_k \phi_k$ )。即在图中 $\Delta=\boldsymbol{L}, \mathrm{e}^{-\mathrm{jkx}}=\phi_k$ ,而 $\mathrm{k}$ 和特征值 $\lambda_{\mathrm{k}}$ 有关。
因此,为了在图上进行傅里叶变换,可以把传统傅里叶变换中的 $\mathrm{e}^{-\mathrm{jk} x}$ 换成 $\phi_k$ ,把频率 $\mathrm{k}$ 换为 特征值 $\lambda_{\mathrm{k}}$。
则图傅里叶变换写作:
$f=\left(f_1, \ldots, f_n\right)$ 是由节点信息构成的n维向量。做个类似的解释,即特征值 $\lambda_k$ 下,$f$ 的 图傅里叶变换(振幅)等于 $f$ 与 $\lambda_k$ 对应的特征向量 $\phi_k$ 的内积。
推广到矩阵形式,图傅里叶变换:
其中, $\hat{f}=\left(\hat{f_1} , \hat{f_2}, \ldots, \hat{f_n}\right)$,即图傅里叶变换,即不同特征值(频率)下对应的振幅构成的向量。 $f=\left(f_1, \ldots, f_n\right)$ 是由节点信息构成的n维向量。
类似的,传统逆傅里叶变换(n个正弦波的叠加):
迁移到图上,$\mathrm{e}^{ikx} \mathrm{e}^{-ikx}=1$,两个基正交,类比于 $\left(\phi_{\mathrm{k}}^{\top} \phi_{\mathrm{k}}\right)_{\mathrm{i}}=1$,则图逆傅里叶变换:
推广到矩阵形式,图逆傅立叶变换:
图卷积(Graph Convolution)
结合图傅立叶变换和卷积定理的结论,我们可以推导出图卷积,首先有:
下面令图为 $f$,卷积核为 $h$,则图卷积为 $f * h$,有:
上式是我按自己的理解推导得来,如有错误,请联系我的邮箱赐教🙏,感谢。
对于卷积核的图傅里叶变换: $\hat{h}=\left(\hat{h}_1, \ldots, \hat{h}_n\right)$, 其中 $\hat{h}_k=\left\langle h, \phi_k\right\rangle, k=1,2 \ldots, n$。
对于把 $\hat{h}$ 组织成对角矩阵 $\operatorname{diag}\left[\hat{h}\left(\lambda_k\right)\right] \in \mathbb{R}^{N \times N}$,个人理解,并不是在改变向量的形状,而是在改变操作方式(转变成矩阵乘法),以更好地表达图卷积的运算。
深度学习中的卷积就是要设计可学习的卷积核,从公式可以看出,就是要设计 $\operatorname{diag}\left[\hat{h}\left(\lambda_1\right), \ldots, \hat{h}\left(\lambda_n\right)\right]$, 由此, 可以直接将其变为卷积核 $\operatorname{diag}\left[\theta_1, \ldots, \theta_n\right]$,而不需要再将卷积核进行傅里叶变换,相当于直接对变换后的参量进行学习,可以把它理解成可训练权重向量。
PS:本人还有一个问题没搞懂,是否图和卷积核要分别计算 $\boldsymbol{\Phi}$ ?
一代GCN
论文:Spectral Networks and Locally Connected Networks on Graphs
由上述图卷积可以得到第一代GCN:
其中,$\boldsymbol{g}_{\boldsymbol{\theta}}=\text{diag}[\theta_1,…,\theta_n]$ 为卷积核,$\sigma$ 是激活函数,$\boldsymbol{x}$ 就是图上对应每个节点的特征构成的向量,$x=\left(x_1, x_2, \ldots, x_n\right)$,这里暂时对每个节点都使用标量,相当于通道数为 1 ,然后经过激活之后,得到输出 $\boldsymbol{y}_{\text {output, }}$ 之后传入下一层。
缺点:
- 需要对拉普拉斯矩阵进行谱分解来求 $\boldsymbol{\Phi}$,在图很大的时候复杂度很高。 另外,还需要计算矩阵乘积,复杂度为 $O\left(n^2\right)$ 。
- 卷积核参数为 $n$,当图很大的时候,$n$ 会很大。
- 卷积核的spatial localization不好。
卷积核的空间定位(spatial localization)是指卷积核在输入数据的空间维度上的操作范围和影响范围。在卷积操作中,卷积核会在输入数据的不同位置上滑动,通过与输入数据的局部区域进行逐元素相乘并求和来生成输出。
在图像处理领域,卷积核的空间定位决定了卷积操作在图像中提取特征的方式。不同大小的卷积核和不同的卷积操作方式可以捕捉到图像中不同尺度和结构的特征。例如,小尺寸的卷积核可以捕捉到图像中的细节特征,而较大尺寸的卷积核则可以捕捉到图像中的整体结构特征。
在图卷积网络中,卷积核的空间定位也很重要。由于图数据不像图像一样具有规则的网格结构,卷积核的设计需要考虑图的拓扑结构。卷积核在图上的空间定位可以用来控制卷积操作在图节点之间传播信息的方式,从而捕捉到图的局部和全局特征。
因此,卷积核的空间定位在卷积操作中起到了至关重要的作用,它决定了卷积操作如何在输入数据的不同位置上进行特征提取。
二代GCN
论文:Convolutional Neural Networks on Graphs with Fast Localized Spectral Filtering
图傅里叶变换是关于特征值(相当于普通傅里叶变换的频率)的函数,也就是 $F\left(\lambda_1\right), \ldots, F\left(\lambda_n\right)$,即 $F(\boldsymbol{\Lambda})$, 因此,将卷积核 $\boldsymbol{g}_\theta$ 写成 $\boldsymbol{g}_\theta(\Lambda)$,然后将 $\boldsymbol{g}_\theta(\Lambda)$ 定义为如下k阶多项式
这里的 $\Lambda$ 为以特征值为对角元素的对角矩阵,所以 $\Lambda^k$ 也是对角矩阵,通过求和之后,还是对角矩阵,就这一点来说,和 $g_\theta$ 本身是对角矩阵是非常吻合的。
将卷积公式带入,可以得到:
可以看出,这一代的GCN不需要做特征分解了,可以直接对Laplacian矩阵做变换,通过事先将Laplacian矩阵求出来,以及 $\boldsymbol{L}^k$ 求出来,前向传播的时候,就可以直接使用,复杂度为 $O\left(K n^2\right)$ 。
那么上式是如何体现localization呢?我们知道,矩阵的$k$次方可以用于求连通性,即1个节点经过$k$步能否到达另一个顶点,矩阵$k$次方结果中对应元素非0的话可达,为0不可达。那么 $\boldsymbol{L}^k$ 所表达的就是 k-hop 内的节点。又可以通过拉普拉斯算子的性质证明,如果两个节点的最短路径大于 $k$ 的话,$\boldsymbol{L}^k$ 在相应位置的元素值为0。
综上,相当于只有n节点的k-hop之内的邻居节点能够传递信息,实际上只利用了节点的K-Localized信息。
另外,作者提出可以使用切比雪夫展开式来近似 $\boldsymbol{L}^k$,因为任何 $\mathbf{k}$ 次多项式都可以使用切比雪夫展开式来近似,由此,引入切比雪夫多项式的 $K$ 阶截断获得 $\boldsymbol{L}^k$ 近似,从而获得对 $g_\theta(\boldsymbol{\Lambda})$ 的近似
其中,$\tilde{\boldsymbol{\Lambda}}=\frac{2}{\lambda_{\max }} \boldsymbol{\Lambda}-\boldsymbol{I}_n $ 为经图拉普拉斯矩阵 $L$ 的最大特征值(即谱半径)缩放后的特征向量矩阵(防止连乘爆炸),$ \boldsymbol{\theta}^{\prime} \in \mathbb{R}^K$ 为一个切比雪夫向量,$\theta_k^{\prime}$ 为第 $k$ 维分量,切比雪夫多项式 $T_k(x)$ 使用递归的方式进行定义:
其中, $T_0(x)=1, T_1(x)=x$ 。
此时,用近似的卷积核带入到原公式,可得:
其中,$\tilde{\boldsymbol{L}}=\frac{2}{\lambda_{\max }} \boldsymbol{L}-\boldsymbol{I}_n$ 。
因此,可以得到输出为:
其中参数向量 $\boldsymbol{\theta}^{\prime} \in \mathbb{R}^{k}$ 需要学习。
三代GCN
论文:Semi-supervised Classification with Graph Convolutional Networks
这一代GCN直接取切比雪夫多项式中 $K=1$,此时模型是 1 阶近似,即每层卷积层只考虑了直接邻域,类似CNN中 $3 \times 3$ 的卷积核。并且,这一代GCN加深了深度而减小了宽度,若要建立多阶 proximity,只需要使用多个卷积层。同时,加入了一些参数约束,如 $\lambda_{\max }=2$ 和引入renormalization trick,大大简化了模型。
下面开始推导,将 $K=1, \quad \lambda_{\max }=2$ 带入可以得到:
最终转换步骤的解释如下:
现在每个卷积核只有2个参数,为了进一步简化,令 $\theta_0^{\prime}=-\theta_1^{\prime}$,此时只含有一个参数 $\theta$:
由于 $\boldsymbol{I}_n+\boldsymbol{D}^{-1 / 2} \boldsymbol{W} \boldsymbol{D}^{-1 / 2}$ 的谱半径 $[0,2]$ 太大,使用renormalization trick:
其中,$\tilde{\boldsymbol{W}}=\boldsymbol{W}+\boldsymbol{I}_n$ (相当于加了self-connection,本来$\boldsymbol{W}$对角元素为0),$\tilde{D}_{i j}=\Sigma_j \tilde{W}_{i j}$ 。
带入卷积公式:
如果推广到多通道,相当于每一个节点的信息是向量,且有多卷积核:
其中,$N$ 是节点数量,$C$ 是通道数,或者称作表示节点的信息维度数。 $\mathrm{X}$ 是 节点的特征矩阵。
相应的卷积核参数变化:
其中,$F$ 为卷积核数量。
那么卷积结果写成矩阵形式为:
上述操作可以叠加多层,对输出$Z$激活一下,就可以作为下一层节点的特征矩阵。
这一代GCN特点:
- 取 $K=1$,相当于直接取邻域信息,类似于 $3 \times 3$ 的卷积核。
- 由于卷积核宽度减小,可以通过增加卷积层数来扩大感受域,从而增强网络的表达能力。
- 增加了参数约束,比如 $\lambda_{\max } \approx 2$,引入重归一化trick。
参考
[1] https://zhuanlan.zhihu.com/p/76296353
[2] https://zhuanlan.zhihu.com/p/54505069
[3] http://xtf615.com/2019/02/24/gcn/
[4] https://zhuanlan.zhihu.com/p/362416124
[5] https://qddmj.cn/gcn-laplacian.htm
[6] https://zhuanlan.zhihu.com/p/170091053
[7] https://qddmj.cn/gcn-laplacian2.htm
[8] https://zhuanlan.zhihu.com/p/41609577
[9] https://zhuanlan.zhihu.com/p/464121739
[10] https://pytorch-geometric.readthedocs.io/en/latest/modules/nn.html#convolutional-layers
[11] https://zhuanlan.zhihu.com/p/60014316
后记
首发于 silencezheng.top,转载请注明出处。

