
0. 前言
这一笔记对应预备知识章节,包括数据操作、数据预处理、线性代数、微积分、概率论等。其中很多知识在学数一的时候都更深入理解过了,但是现在发现忘的差不多了,哎~
对应实践:https://github.com/silenceZheng66/deep_learning/blob/master/d2l/0x02.ipynb
在M1芯片的设备上使用miniforge安装pytorch:conda install -c pytorch pytorch
1. 数据操作
1.1. 概念
1.1.1 张量(tensor)
即n维数组,无论使用哪个深度学习框架,它的张量类(在MXNet中为ndarray, 在PyTorch和TensorFlow中为Tensor)都与Numpy的ndarray类似。 但深度学习框架又比Numpy的ndarray多一些重要功能: 首先,GPU很好地支持加速计算,而NumPy仅支持CPU计算; 其次,张量类支持自动微分。 这些功能使得张量类更适合深度学习。
张量表示由一个数值组成的数组,这个数组可能有多个维度。 具有一个轴的张量对应数学上的向量(vector); 具有两个轴的张量对应数学上的矩阵(matrix); 具有两个轴以上的张量没有特殊的数学名称。张量中的每个值都称为张量的元素(element)。
1.1.2. 运算符
我们的兴趣不仅限于读取数据和写入数据。 我们想在这些数据上执行数学运算,其中最简单且最有用的操作是按元素(elementwise)运算。 它们将标准标量运算符应用于数组的每个元素。 对于将两个数组作为输入的函数,按元素运算将二元运算符应用于两个数组中的每对位置对应的元素。 我们可以基于任何从标量到标量的函数来创建按元素函数。
对于任意具有相同形状的张量, 常见的标准算术运算符(+、-、*、/和**)都可以被升级为按元素运算。 我们可以在同一形状的任意两个张量上调用按元素操作。
1.1.3. 广播机制
在上面的部分中,我们看到了如何在相同形状的两个张量上执行按元素操作。 在某些情况下,即使形状不同,我们仍然可以通过调用广播机制(broadcasting mechanism)来执行按元素操作。 这种机制的工作方式如下:首先,通过适当复制元素来扩展一个或两个数组, 以便在转换之后,两个张量具有相同的形状。 其次,对生成的数组执行按元素操作。
1.1.4. 索引和切片
就像在任何其他Python数组中一样,张量中的元素可以通过索引访问。 与任何Python数组一样:第一个元素的索引是0,最后一个元素索引是-1; 可以指定范围以包含第一个元素和最后一个之前的元素。例如:我们可以用[-1]选择最后一个元素,可以用[1:3]选择第二个和第三个元素。
1.1.5. 内存变动
运行一些操作可能会导致为新结果分配内存。 例如,如果我们用Y=X+Y,我们将取消引用Y指向的张量,而是指向新分配的内存处的张量。Python的id()函数给我们提供了内存中引用对象的确切地址。 运行Y=Y+X后,我们会发现id(Y)指向另一个位置。 这是因为Python首先计算Y+X,为结果分配新的内存,然后使Y指向内存中的这个新位置。
我们不希望内存在不必要时发生重新分配的情况,原因有两个:首先,我们不想总是不必要地分配内存。 在机器学习中,我们可能有数百兆的参数,并且在一秒内多次更新所有参数。 通常情况下,我们希望原地执行这些更新。 其次,如果我们不原地更新,其他引用仍然会指向旧的内存位置, 这样我们的某些代码可能会无意中引用旧的参数。
在这种情况下,我们可以使用切片表示法将操作的结果分配给先前分配的数组,例如Y[:]=<expression>。
在节省内存开销方面,如果在后续计算中没有重复使用X, 我们也可以使用X[:]=X+Y或X+=Y来减少操作的内存开销。
1.1.6. 对象转换
将深度学习框架定义的张量转换为NumPy张量(ndarray)很容易,反之也同样容易。 注意torch张量和numpy数组将共享它们的底层内存,就地操作更改一个张量也会同时更改另一个张量。
要将大小为1的张量转换为Python标量,可以调用item函数或Python的内置函数。
1.2. 以PyTorch为例,列举常见操作
虽然它被称为PyTorch,但是代码中使用torch而不是pytorch。
import torch
首先,我们可以使用arange创建一个行向量x。这个行向量包含以0开始的前12个整数,它们默认创建为整数。也可指定创建类型为浮点数。例如,张量x中有 12 个元素。除非额外指定,新的张量将存储在内存中,并采用基于CPU的计算。
x=torch.arange(12)
可以通过张量的shape属性来访问张量(沿每个轴的长度)的形状。
x.shape
如果只想知道张量中元素的总数,即形状的所有元素乘积,可以检查它的大小(size)。 因为这里在处理的是一个向量,所以它的shape与它的size相同。
x.numel()
要想改变一个张量的形状而不改变元素数量和元素值,可以调用reshape函数。 例如,可以把张量x从形状为(12,)的行向量转换为形状为(3,4)的矩阵。 这个新的张量包含与转换前相同的值,但是它被看成一个3行4列的矩阵。 要重点说明一下,虽然张量的形状发生了改变,但其元素值并没有变。 注意,通过改变张量的形状,张量的大小(size)不会改变。我们可以通过-1来调用此自动计算出维度的功能。 即我们可以用x.reshape(-1,4)或x.reshape(3,-1)来取代x.reshape(3,4)。
X=x.reshape(3,4)
有时,我们希望使用全0、全1、其他常量,或者从特定分布中随机采样的数字来初始化矩阵。 我们可以创建一个形状为(2,3,4)的张量,其中所有元素都设置为0。torch.ones((2,3,4))则创建元素全为1的张量,但默认数据类型为float。
torch.zeros((2,3,4))
#结果:
tensor([[[0.,0.,0.,0.],
[0.,0.,0.,0.],
[0.,0.,0.,0.]],
[[0.,0.,0.,0.],
[0.,0.,0.,0.],
[0.,0.,0.,0.]]])
有时我们想通过从某个特定的概率分布中随机采样来得到张量中每个元素的值。 例如,当我们构造数组来作为神经网络中的参数时,我们通常会随机初始化参数的值。 以下代码创建一个形状为(3,4)的张量。 其中的每个元素都从均值为0、标准差为1的标准高斯分布(正态分布)中随机采样。
torch.randn(3,4)
我们还可以通过提供包含数值的Python列表(或嵌套列表),来为所需张量中的每个元素赋予确定值。 在这里,最外层的列表对应于轴0,内层的列表对应于轴1。
torch.tensor([[2,1,4,3],[1,2,3,4],[4,3,2,1]])
在下面的例子中,我们使用逗号来表示一个具有5个元素的元组,其中每个元素都是按元素操作的结果。
x=torch.tensor([1.0,2,4,8])
y=torch.tensor([2,2,2,2])
x+y,x-y,x*y,x/y,x**y# **运算符是求幂运算
#结果:
(tensor([3.,4.,6.,10.]),
tensor([-1.,0.,2.,6.]),
tensor([2.,4.,8.,16.]),
tensor([0.5000,1.0000,2.0000,4.0000]),
tensor([1.,4.,16.,64.]))
“按元素”方式可以应用更多的计算,包括像求幂这样的一元运算符。
torch.exp(x)
我们也可以把多个张量连结(concatenate)在一起, 把它们端对端地叠起来形成一个更大的张量。 我们只需要提供张量列表,并给出沿哪个轴连结。 下面的例子分别演示了当我们沿行(轴-0,形状的第一个元素) 和按列(轴-1,形状的第二个元素)连结两个矩阵时,会发生什么情况。 我们可以看到,第一个输出张量的轴-0长度(6)是两个输入张量轴-0长度的总和(3+3); 第二个输出张量的轴-1长度(8)是两个输入张量轴-1长度的总和(4+4)。
X=torch.arange(12,dtype=torch.float32).reshape((3,4))
Y=torch.tensor([[2.0,1,4,3],[1,2,3,4],[4,3,2,1]])
torch.cat((X,Y),dim=0),torch.cat((X,Y),dim=1)
#结果:
(tensor([[0.,1.,2.,3.],[4.,5.,6.,7.],[8.,9.,10.,11.],[2.,1.,4.,3.],[1.,2.,3.,4.],[4.,3.,2.,1.]]),
tensor([[0.,1.,2.,3.,2.,1.,4.,3.],[4.,5.,6.,7.,1.,2.,3.,4.],[8.,9.,10.,11.,4.,3.,2.,1.]]))
有时,我们想通过逻辑运算符构建二元张量。 以X==Y为例: 对于每个位置,如果X和Y在该位置相等,则新张量中相应项的值为1。 这意味着逻辑语句X==Y在该位置处为真,否则该位置为0。
X==Y
#结果:
tensor([[False,True,False,True],[False,False,False,False],[False,False,False,False]])
对张量中的所有元素进行求和,会产生一个单元素张量。
X.sum()
#结果:
tensor(66.)
在大多数情况下,我们将沿着数组中长度为1的轴进行广播,如下例子:
a=torch.arange(3).reshape((3,1))
b=torch.arange(2).reshape((1,2))
a,b
#结果:
(tensor([[0],[1],[2]]),tensor([[0,1]]))
由于a和b分别是3×1和1×2矩阵,如果让它们相加,它们的形状不匹配。 我们将两个矩阵广播为一个更大的3×2矩阵,如下所示:矩阵a将复制列, 矩阵b将复制行,然后再按元素相加。
a+b
#结果:
tensor([[0,1],[1,2],[2,3]])
如下所示,我们可以用[-1]选择最后一个元素,可以用[1:3]选择第二个和第三个元素:
X[-1],X[1:3]
除读取外,我们还可以通过指定索引来将元素写入矩阵。
X[1,2]=9
如果我们想为多个元素赋值相同的值,我们只需要索引所有元素,然后为它们赋值。 例如,[0:2,:]访问第1行和第2行,其中“:”代表沿轴1(列)的所有元素。虽然我们讨论的是矩阵的索引,但这也适用于向量和超过2个维度的张量。
X[0:2,:]=12
将深度学习框架定义的张量转换为NumPy张量(ndarray)很容易,反之也同样容易。 torch张量和numpy数组将共享它们的底层内存,就地操作更改一个张量也会同时更改另一个张量。
A=X.numpy()
B=torch.tensor(A)
type(A),type(B)
#结果:
(numpy.ndarray,torch.Tensor)
要将大小为1的张量转换为Python标量,我们可以调用item函数或Python的内置函数。
a=torch.tensor([3.5])
a,a.item(),float(a),int(a)
#结果:
(tensor([3.5000]),3.5,3.5,3)
2. 数据预处理
在Python中常用的数据分析工具中,我们通常使用pandas软件包。 像庞大的Python生态系统中的许多其他扩展包一样,pandas可以与张量兼容。 本节我们将简要介绍使用pandas预处理原始数据,并将原始数据转换为张量格式的步骤。
2.1. 读取数据集
要从创建的CSV文件中加载原始数据集,我们导入pandas包并调用read_csv函数。
data=pd.read_csv(data_file)
print(data)
#结果:
NumRooms Alley
0 NaN Pave
1 2.0 NaN
2 4.0 NaN
3 NaN NaN
2.2. 处理缺失值
注意,“NaN”项代表缺失值。 为了处理缺失的数据,典型的方法包括插值法和删除法, 其中插值法用一个替代值弥补缺失值,而删除法则直接忽略缺失值。
在对上面例子的处理中,我们将考虑插值法。通过位置索引iloc,我们将data分成inputs和outputs, 其中前者为data的前两列,而后者为data的最后一列。 对于inputs中缺少的数值,我们用同一列的均值替换“NaN”项。
inputs,outputs=data.iloc[:,0:2],data.iloc[:,2]
inputs=inputs.fillna(inputs.mean())
print(inputs)
#结果:
NumRooms Alley
0 3.0 Pave
1 2.0 NaN
2 4.0 NaN
3 3.0 NaN
对于inputs中的类别值或离散值,我们将“NaN”视为一个类别。 由于“巷子类型”(“Alley”)列只接受两种类型的类别值“Pave”和“NaN”,pandas可以自动将此列转换为两列“Alley_Pave”和“Alley_nan”。 巷子类型为“Pave”的行会将“Alley_Pave”的值设置为1,“Alley_nan”的值设置为0。 缺少巷子类型的行会将“Alley_Pave”和“Alley_nan”分别设置为0和1。Pandas中的get_dummies方法主要用于对类别型特征做One-Hot编码。dummy_na参数默认为False,增加一列表示空缺值,如果为False就忽略空缺值。
inputs=pd.get_dummies(inputs,dummy_na=True)
print(inputs)
#结果:
NumRooms Alley_Pave Alley_nan
0 3.0 1 0
1 2.0 0 1
2 4.0 0 1
3 3.0 0 1
2.3. 转换为张量
现在inputs和outputs中的所有条目都是数值类型,它们需要转换为张量格式进行下一步操作。
import torch
X,y=torch.tensor(inputs.values),torch.tensor(outputs.values)
3. 线性代数
3.1. 基础概念
标量(scalar):称仅包含一个数值的叫标量。标量由只有一个元素的张量表示时如x=torch.tensor(3.0)。
变量(variable):符号(x、y等)称为变量,它们表示未知的标量值。
向量(vector):可以将向量视为标量值组成的列表。 我们将这些标量值称为向量的元素(element)或分量(component)。向量的长度通常称为向量的维度。 当向量表示数据集中的样本时,它们的值具有一定的现实意义。例如,如果我们正在研究医院患者可能面临的心脏病发作风险,我们可能会用一个向量来表示每个患者, 其分量为最近的生命体征、胆固醇水平、每天运动时间等。我们通过一维张量处理向量,其长度任意,通过张量的索引来访问向量中任一元素。
维度(dimension):向量或轴的维度被用来表示向量或轴的长度,即向量或轴的元素数量。 然而,张量的维度用来表示张量具有的轴数。 在这个意义上,张量的某个轴的维数就是这个轴的长度。
矩阵(matrix):正如向量将标量从零阶推广到一阶,矩阵将向量从一阶推广到二阶,在代码中表示为具有两个轴的张量。当调用函数来实例化张量时, 我们可以通过指定两个分量m和n来创建一个形状为m×n的矩阵,如A=torch.arange(20).reshape(5,4)。在代码中访问矩阵的转置A.T。
张量(tensor):在线性代数中指代数对象,为我们提供了描述具有任意数量轴的n维数组的通用方法。向量是一阶张量,矩阵是二阶张量。它们的索引机制与矩阵类似。
点积(dot product):也就是内积,给定两个向量x,y∈Rd, 它们的点积(dot product)x⊤y(或⟨x,y⟩) 是相同位置的按元素乘积的和。点积在很多场合都很有用。 例如,给定一组由向量x∈Rd表示的值, 和一组由w∈Rd表示的权重。x中的值根据权重w的加权和, 可以表示为点积x⊤w。 当权重为非负数且和为1(即(∑i=1dwi=1))时, 点积表示加权平均(weighted average)。 将两个向量规范化得到单位长度后,点积表示它们夹角的余弦。 在代码中使用torch.dot(x,y)表示,注意点积中只接收向量(1维)。
矩阵-向量积(matrix-vector product):将矩阵看作一个列向量,其中每一个元素为一个行向量,则矩阵-向量积为将该列向量的每个元素替换为对应行向量与向量的点积。在代码中使用张量表示矩阵-向量积,我们使用mv函数,接收一个矩阵(2维)和一个向量(1维)。 当我们为矩阵A和向量x调用torch.mv(A,x)时,会执行矩阵-向量积。 注意,A的列维数(沿轴1的长度)必须与x的维数(其长度)相同。
矩阵乘法(matrix-matrix multiplication):设A为n×k矩阵、B为k×m矩阵,可以将矩阵-矩阵乘法AB看作是简单地执行m次矩阵-向量积,并将结果拼接在一起,形成一个n×m矩阵。在代码中:torch.mm(A,B)
表示法:在《动手学深度学习》中,标量变量由普通小写字母表示(例如,x、y和z),用R表示所有(连续)实数标量的空间,将向量记为粗体、小写的符号 (例如,x、y和z),认为列向量是向量的默认方向,通常用粗体、大写字母来表示矩阵 (例如,X、Y和Z),张量用特殊字体的大写字母表示(例如,X、Y和Z)。
3.2. 张量算法
当我们开始处理图像时,张量将变得更加重要,图像以n维数组形式出现, 其中3个轴对应于高度、宽度,以及一个通道(channel)轴, 用于表示颜色通道(红色、绿色和蓝色)。
给定具有相同形状的任意两个张量,任何按元素二元运算的结果都将是相同形状的张量。例如,将两个相同形状的矩阵相加,会在这两个矩阵上执行元素加法。
A=torch.arange(20,dtype=torch.float32).reshape(5,4)
B=A.clone()# 通过分配新内存,将A的一个副本分配给B
A, A+B
两个矩阵的按元素乘法称为Hadamard积(Hadamard product)(数学符号⊙)。
A*B
将张量乘以或加上一个标量不会改变张量的形状,其中张量的每个元素都将与标量相加或相乘。
A*2, A+2
3.3. 降维
我们可以对任意张量进行的一个有用的操作是计算其元素的和。 在数学表示法中,我们使用∑符号表示求和。在代码中,我们可以调用计算求和的函数x.sum()。
默认情况下,调用求和函数会沿所有的轴降低张量的维度,使它变为一个标量。 我们还可以指定张量沿哪一个轴来通过求和降低维度。 以矩阵为例,为了通过求和所有行的元素来降维(轴0),我们可以在调用函数时指定axis=0。 由于输入矩阵沿0轴降维以生成输出向量,因此输入轴0的维数在输出形状中消失。
A_sum_axis0=A.sum(axis=0)
A_sum_axis0,A_sum_axis0.shape
#结果:
(tensor([40.,45.,50.,55.]),torch.Size([4]))
指定axis=1将通过汇总所有列的元素降维(轴1)。因此,输入轴1的维数在输出形状中消失。
A_sum_axis1=A.sum(axis=1)
A_sum_axis1,A_sum_axis1.shape
#结果:
(tensor([6.,22.,38.,54.,70.]),torch.Size([5]))
沿着行和列对矩阵求和,等价于对矩阵的所有元素进行求和。如A.sum(axis=[0,1])。
一个与求和相关的量是平均值(mean或average)。 我们通过将总和除以元素总数来计算平均值。 在代码中,我们可以调用函数来计算任意形状张量的平均值。
A.mean(),A.sum()/A.numel() #两者等价
同样,计算平均值的函数也可以沿指定轴降低张量的维度。
A.mean(axis=0),A.sum(axis=0)/A.shape[0]
#结果:
(tensor([8.,9.,10.,11.]),tensor([8.,9.,10.,11.]))
3.3.1. 非降维求和
有时在调用函数来计算总和或均值时保持轴数不变会很有用。
sum_A=A.sum(axis=1,keepdims=True)
sum_A
#结果:
tensor([[6.],[22.],[38.],[54.],[70.]])
例如,由于sum_A在对每行进行求和后仍保持两个轴,我们可以通过广播将A除以sum_A。如:A/sum_A
如果我们想沿某个轴计算A元素的累积总和, 比如axis=0(按行计算),我们可以调用cumsum函数。 此函数不会沿任何轴降低输入张量的维度。
A.cumsum(axis=0)
#原本A:
tensor([[0.,1.,2.,3.],
[4.,5.,6.,7.],
[8.,9.,10.,11.],
[12.,13.,14.,15.],
[16.,17.,18.,19.]])
#结果:
tensor([[0.,1.,2.,3.],
[4.,6.,8.,10.],
[12.,15.,18.,21.],
[24.,28.,32.,36.],
[40.,45.,50.,55.]])
3.4 范数
线性代数中最有用的一些运算符是范数(norm)。 非正式地说,一个向量的范数告诉我们一个向量有多大。 这里考虑的大小(size)概念不涉及维度,而是分量的大小。
在线性代数中,向量范数是将向量映射到标量的函数f。 给定任意向量x,向量范数要满足一些属性。 第一个性质是如果我们按常数因子α缩放向量的所有元素, 其范数也会按相同常数因子的绝对值缩放。第二个性质是我们熟悉的三角不等式f(x+y)\<=f(x)+f(y)。第三个性质简单地说范数必须是非负的,这是有道理的。因为在大多数情况下,任何东西的最小的大小是0。 最后一个性质要求范数最小为0,当且仅当向量全由0组成。
假设n维向量x中的元素是x1,…,xn,其L2范数是向量元素平方和的平方根。在代码中,我们可以按如下方式计算向量的L2范数。在深度学习中,我们更经常地使用L2范数的平方。
u=torch.tensor([3.0,-4.0])
torch.norm(u)
#结果:
tensor(5.)
L1范数,表示为向量元素的绝对值之和。与L2范数相比,L1范数受异常值的影响较小。 为了计算L1范数,我们将绝对值函数和按元素求和组合起来。
torch.abs(u).sum()
#结果:
tensor(7.)
L2范数和L1范数都是更一般的Lp范数的特例。
类似于向量的L2范数,矩阵X∈Rm×n的Frobenius范数(Frobenius norm)是矩阵元素平方和的平方根。Frobenius范数满足向量范数的所有性质,它就像是矩阵形向量的L2范数。 调用以下函数将计算矩阵的Frobenius范数。
torch.norm(torch.ones((4,9)))
#结果:
tensor(6.)
在深度学习中,我们经常试图解决优化问题:最大化分配给观测数据的概率;最小化预测和真实观测之间的距离。 用向量表示物品(如单词、产品或新闻文章),以便最小化相似项目之间的距离,最大化不同项目之间的距离。 目标,或许是深度学习算法最重要的组成部分(除了数据),通常被表达为范数。
4. 微积分和自动微分
在深度学习中,我们“训练”模型,不断更新它们,使它们在看到越来越多的数据时变得越来越好。 通常情况下,变得更好意味着最小化一个损失函数(loss function), 即一个衡量“我们的模型有多糟糕”这个问题的分数。 最终,我们真正关心的是生成一个模型,它能够在从未见过的数据上表现良好。 但“训练”模型只能将模型与我们实际能看到的数据相拟合。 因此,我们可以将拟合模型的任务分解为两个关键问题:
- 优化(optimization):用模型拟合观测数据的过程;
- 泛化(generalization):数学原理和实践者的智慧,能够指导我们生成出有效性超出用于训练的数据集本身的模型。
总结:
- 微分和积分是微积分的两个分支,前者可以应用于深度学习中的优化问题。
- 导数可以被解释为函数相对于其变量的瞬时变化率,它也是函数曲线的切线的斜率。
- 梯度是一个向量,其分量是多变量函数相对于其所有变量的偏导数。
- 链式法则使我们能够微分复合函数。
- 深度学习框架可以自动计算导数:我们首先将梯度附加到想要对其计算偏导数的变量上。然后我们记录目标值的计算,执行它的反向传播函数,并访问得到的梯度。
4.1. 导数、微分、偏导
我们首先讨论导数的计算,这是几乎所有深度学习优化算法的关键步骤。 在深度学习中,我们通常选择对于模型参数可微的损失函数。 简而言之,对于每个参数, 如果我们把这个参数增加或减少一个无穷小的量,我们可以知道损失会以多快的速度增加或减少。
假设我们有一个函数f,其输入和输出都是标量。 导数定义不用多说,如果f′(a)存在,则称f在a处是可微(differentiable)的。如果f在一个区间内的每个数上都是可微的,则此函数在此区间中是可微的。可以将导数定义中的导数f′(x)解释为f(x)相对于x的瞬时(instantaneous)变化率。 所谓的瞬时变化率是基于x中的变化h,且h接近0。
要了解微分,以及对函数微分的法则。例如Dx^n = nx^(n-1),其中D为微分运算符。还要了解求偏导,这些都是基础。
4.2. 梯度
我们可以连结一个多元函数对其所有变量的偏导数,以得到该函数的梯度(gradient)向量。 具体而言,设函数f:Rn→R的输入是一个n维向量x=[x1,x2,…,xn]⊤,并且输出是一个标量。 函数f(x)相对于x的梯度是一个包含n个偏导数的向量
,其中∇xf(x)通常在没有歧义时被∇f(x)取代。梯度对于设计深度学习中的优化算法有很大用处。
假设x为n维向量,在微分多元函数时经常使用以下规则:
- 对于所有 $\mathbf{A} \in \mathbb{R}^{m \times n}$, 都有 $\nabla_{\mathbf{x}} \mathbf{A} \mathbf{x}=\mathbf{A}^{\top}$
- 对于所有 $\mathbf{A} \in \mathbb{R}^{n \times m}$, 都有 $\nabla_{\mathbf{x}} \mathbf{x}^{\top} \mathbf{A}=\mathbf{A}$
-对于所有 $\mathbf{A} \in \mathbb{R}^{n \times n}$, 都有 $\nabla_{\mathbf{x}} \mathbf{x}^{\top} \mathbf{A} \mathbf{x}=\left(\mathbf{A}+\mathbf{A}^{\top}\right) \mathbf{x}$ - $\nabla_{\mathbf{x}}|\mathbf{x}|^{2}=\nabla_{\mathbf{x}} \mathbf{x}^{\top} \mathbf{x}=2 \mathbf{x}$
同样,对于任何矩阵X,都有 $\nabla \mathbf{X}|\mathbf{X}|_{F}^{2}=2 \mathbf{X}$。
4.3. 链式法则
然而,上面方法可能很难找到梯度。 这是因为在深度学习中,多元函数通常是复合(composite)的, 所以我们可能没法应用上述任何规则来微分这些函数。 幸运的是,链式法则使我们能够微分复合函数。
让我们先考虑单变量函数。假设函数y=f(u)和u=g(x)都是可微的,根据链式法则有
当处于函数具有任意数量的变量的情况下。假设可微分函数y有变量u1,u2,…,um,其中每个可微分函数ui都有变量x1,x2,…,xn。 注意,y是x1,x2,…,xn的函数。 对于任意i=1,2,…,n,链式法则给出:
4.4. 自动微分
求导是几乎所有深度学习优化算法的关键步骤。 虽然求导的计算很简单,只需要一些基本的微积分。 但对于复杂的模型,手工进行更新是一件很痛苦的事情(而且经常容易出错)。
深度学习框架通过自动计算导数,即自动微分(automatic differentiation)来加快求导。 实际中,根据我们设计的模型,系统会构建一个计算图(computational graph), 来跟踪计算是哪些数据通过哪些操作组合起来产生输出。 自动微分使系统能够随后反向传播梯度。 这里,反向传播(backpropagate)意味着跟踪整个计算图,填充关于每个参数的偏导数。设y为关于x的函数,调用y.backward()反向传播计算x的梯度x.grad。
例如对于:$e=(a+b) *(b+1)$
可以得到计算图如下: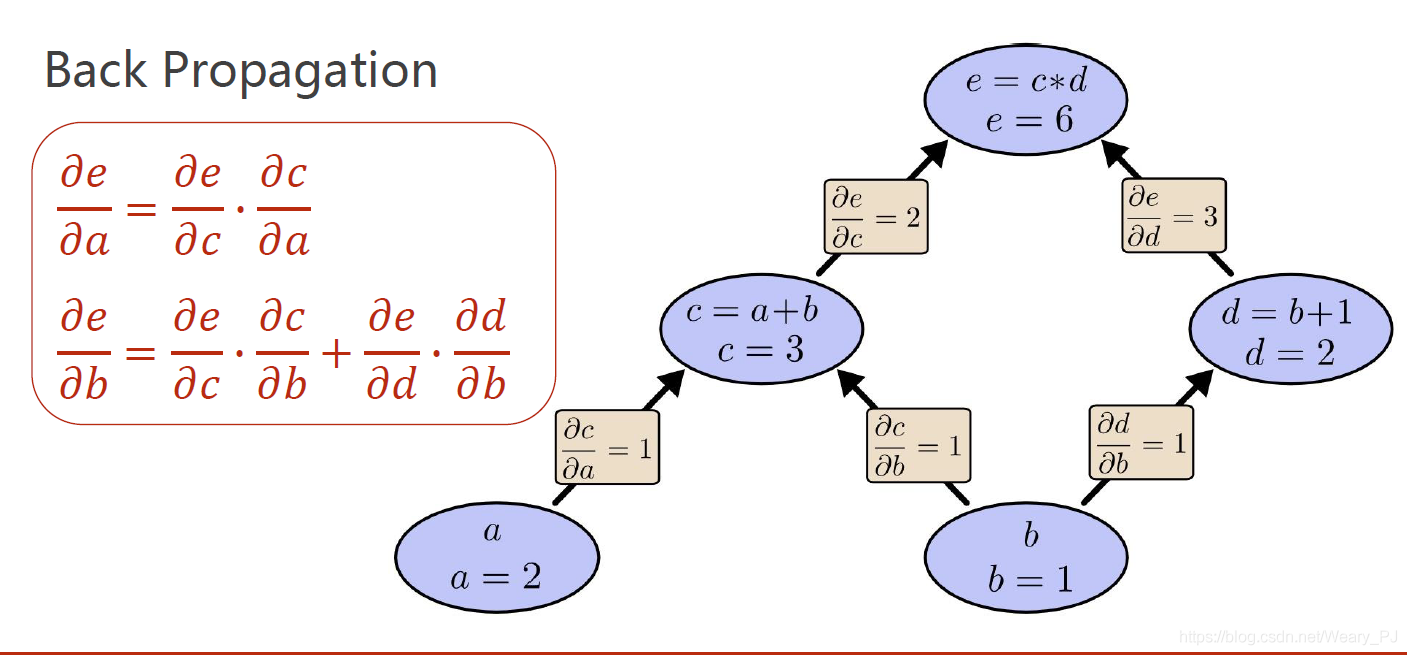
反向传播参考:https://blog.csdn.net/Weary_PJ/article/details/105706318
4.4.1. 非标量变量的反向传播
当y不是标量时,向量y关于向量x的导数的最自然解释是一个矩阵。 对于高阶和高维的y和x,求导的结果可以是一个高阶张量。
然而,虽然这些更奇特的对象确实出现在高级机器学习中(包括深度学习中), 但当我们调用向量的反向计算时,我们通常会试图计算一批训练样本中每个组成部分的损失函数的导数。 这里,我们的目的不是计算微分矩阵,而是单独计算批量中每个样本的偏导数之和。
4.4.2. 分离计算
有时,我们希望将某些计算移动到记录的计算图之外。 例如,假设y是作为x的函数计算的,而z则是作为y和x的函数计算的。 想象一下,我们想计算z关于x的梯度,但由于某种原因,我们希望将y视为一个常数, 并且只考虑到x在y被计算后发挥的作用。
在这里,我们可以分离y来返回一个新变量u,该变量与y具有相同的值, 但丢弃计算图中如何计算y的任何信息。 换句话说,梯度不会向后流经u到x。
为了实现自动微分,PyTorch跟踪所有涉及张量的操作,可能需要为其计算梯度(即require_grad为True)。 这些操作记录为有向图。在代码上,上述分离计算可以通过使用detach()方法在张量上构造一个新视图,该张量声明为不需要梯度,即从进一步跟踪操作中将其排除在外,因此不记录涉及该视图的子图。即对应上述的情况,令u=y.detach(),使用z=u*x替代原本的z=y*x。
4.4.3. Python控制流的梯度计算
使用自动微分的一个好处是:即使构建函数的计算图需要通过Python控制流(例如,条件、循环或任意函数调用),我们仍然可以计算得到的变量的梯度。在下面的代码中,while循环的迭代次数和if语句的结果都取决于输入a的值。
def f(a):
b=a*2
while b.norm()<1000:
b=b*2
if b.sum()>0:
c=b
else:
c=100*b
return c
# 计算梯度
a=torch.randn(size=(),requires_grad=True)
d=f(a)
d.backward()
我们现在可以分析上面定义的f函数。 请注意,它在其输入a中是分段线性的。 换言之,对于任何a,存在某个常量标量k,使得f(a)=k*a,其中k的值取决于输入a。 因此,我们可以用d/a验证梯度是否正确。a.grad==d/a结果为真。
5. 概率
简单地说,机器学习就是做出预测。
根据病人的临床病史,我们可能想预测他们在下一年心脏病发作的概率。 在飞机喷气发动机的异常检测中,我们想要评估一组发动机读数为正常运行情况的概率有多大。 在强化学习中,我们希望智能体(agent)能在一个环境中智能地行动。 这意味着我们需要考虑在每种可行的行为下获得高奖励的概率。 当我们建立推荐系统时,我们也需要考虑概率。 例如,假设我们为一家大型在线书店工作,我们可能希望估计某些用户购买特定图书的概率。 为此,我们需要使用概率学。 概率是一种灵活的语言,用于说明我们的确定程度,并且它可以有效地应用于广泛的领域中。
对于概率(probability)和统计(statistics):概率是已知模型和参数,推数据。统计是已知数据,推模型和参数。
5.1. 基本概率论
以掷骰子为例,想知道看到1的几率有多大,而不是看到另一个数字。 如果骰子是公平的,那么所有六个结果{1,…,6}都有相同的可能发生, 因此我们可以说1发生的概率为6分之1。
然而现实生活中,对于我们从工厂收到的真实骰子,我们需要检查它是否有瑕疵。 检查骰子的唯一方法是多次投掷并记录结果。 对于每个骰子,我们将观察到{1,…,6}中的一个值。 对于每个值,一种自然的方法是将它出现的次数除以投掷的总次数, 即此事件(event)概率的估计值。大数定律(law of large numbers)告诉我们: 随着投掷次数的增加,这个估计值会越来越接近真实的潜在概率。
在统计学中,我们把从概率分布中抽取样本的过程称为抽样(sampling)。 笼统来说,可以把分布(distribution)看作是对事件的概率分配, 稍后我们将给出的更正式定义。 将概率分配给一些离散选择的分布称为多项分布(multinomial distribution)。
在代码中multinomial.Multinomial函数创建由 total_count 和 probs 或 logits(但不是两者)参数化的多项分布。 probs(概率)的最内层维度索引种类,所有其他维度索引批次。total_count表示总的实验次数。如:multinomial.Multinomial(10,fair_probs).sample()表示在fair_probs的概率下进行了10次实验得到的分布情况。在此基础上除10即可得到真实概率的估计。
5.1.1. 概率论公理
在处理骰子掷出时,我们将集合S={1,2,3,4,5,6}称为样本空间(sample space)或结果空间(outcome space), 其中每个元素都是结果(outcome)。事件(event)是一组给定样本空间的随机结果。 例如,“看到5”({5})和“看到奇数”({1,3,5})都是掷出骰子的有效事件。 注意,如果一个随机实验的结果在A中,则事件A已经发生。 也就是说,如果投掷出3点,因为3∈{1,3,5},我们可以说,“看到奇数”的事件发生了。概率(probability)可以被认为是将集合映射到真实值的函数。
性质:
- 概率非负
- 全样本空间概率为1
- 对于互斥(mutually exclusive)事件(对于所有i≠j都有Ai∩Aj=∅)的任意一个可数序列A1,A2,…,序列中任意一个事件发生的概率等于它们各自发生的概率之和。
5.1.2. 随机变量
在我们掷骰子的随机实验中,我们引入了随机变量(random variable)的概念。 随机变量几乎可以是任何数量,并且它可以在随机实验的一组可能性中取一个值。 考虑一个随机变量X,其值在掷骰子的样本空间S={1,2,3,4,5,6}中。 我们可以将事件“看到一个5”表示为{X=5}或X=5, 其概率表示为P({X=5})或P(X=5)。 通过P(X=a),我们区分了随机变量X和X可以采取的值(例如a)。
然而,这可能会导致繁琐的表示。 为了简化符号,一方面,我们可以将P(X)表示为随机变量X上的分布(distribution): 分布告诉我们X获得某一值的概率。 另一方面,我们可以简单用P(a)表示随机变量取值a的概率。 由于概率论中的事件是来自样本空间的一组结果,因此我们可以为随机变量指定值的可取范围。 例如,P(1≤X≤3)表示事件{1≤X≤3}, 即{X=1,2,or,3}的概率。 等价地,P(1≤X≤3)表示随机变量X从{1,2,3}中取值的概率。这一节主要讨论离散型随机变量,连续型不咋考虑。
5.2. 处理多个随机变量
例如图像包含数百万像素,因此有数百万个随机变量。 在许多情况下,图像会附带一个标签(label),标识图像中的对象。 我们也可以将标签视为一个随机变量。 我们甚至可以将所有元数据视为随机变量,例如位置、时间、光圈、焦距、ISO、对焦距离和相机类型。 所有这些都是联合发生的随机变量。 当我们处理多个随机变量时,会有若干个变量是我们感兴趣的。
5.2.1. 一些基本概念
联合概率(joint probability):$P(A=a, B=b)$,联合概率可以回答:A=a和B=b同时满足的概率是多少的问题,但对于任何a和b的取值,P(A=a,B=b)≤P(A=a)。
条件概率(conditional probability):用P(B=b∣A=a)表示它,它是B=b的概率,前提是A=a已发生。
贝叶斯定理(Bayes’ theorem):根据乘法法则(multiplication rule)可得到 $P(A, B)=P(B \mid A) P(A)$ 。根据对称性, 可得到 $P(A, B)=P(A \mid B) P(B)$ 。根据两式假设P(B)>0,求解其中一个条件变量,我们得到:
注意这里使用紧凑的表示法: 其中 $P(A, B)$ 是一个联合分布(joint distribution), $P(A \mid B)$ 是一个条件分布 (conditional distribution)。这种分布可以在给定值 $A=a, B=b$ 上进行求值。
边际化(marginalization):为了能进行事件概率求和,我们需要加法法则(sum rule), 即B的概率相当于计算A的所有可能选择,并将所有选择的联合概率聚合在一起:
这也称为边际化(marginalization)。边际化结果的概率或分布称为边缘概率(marginal probability) 或边缘分布(marginal distribution)。
依赖(dependence)与独立(independence):如果两个随机变量A和B是独立的,意味着事件A的发生跟B事件的发生无关。 在这种情况下,通常将这一点表述为A⊥B。 根据贝叶斯定理,得到P(A∣B)=P(A)。 在所有其他情况下,我们称A和B依赖。 比如,两次连续抛出一个骰子的事件是相互独立的。 相比之下,灯开关的位置和房间的亮度并不是(因为可能存在灯泡坏掉、电源故障,或者开关故障)。两个随机变量是独立的,当且仅当两个随机变量的联合分布是其各自分布的乘积。
期望(expectation,或平均值(average)):均值。
方差(variance):数据与平均数之差平方和的平均数,方差的平方根被称为标准差(standared deviation)。随机变量函数的方差衡量的是:当从该随机变量分布中采样不同值x时, 函数值偏离该函数的期望的程度。
似然函数(Likelihood Function):似然也就是可能性。在统计中,似然函数和概率函数是两个不同的概念。
对于这个函数: $p(x \mid \theta)$ 输入有两个: $\mathrm{x}$ 表示某一个具体的数据; $\theta$ 表示模型的参数。
如果 $\theta$ 是已知确定的, $x$ 是变量, 这个函数叫做概率函数(probability function), 它描述对于不同的样本点 $x$, 其出现概率是多少。
如果 $x$ 是已知确定的, $\theta$ 是变量, 这个函数叫做似然函数(likelihood function), 它描述对于不同的模型参数, 出现 $x$ 这个样本点的概率是多少。
最大似然估计(Maximum Likelihood Estimation, MLE):属于统计领域问题,利用已知的样本结果信息,反推最具有可能(最大概率)导致这些样本结果出现的模型参数值。其中似然即可能性。
极大似然估计中采样需满足一个重要的假设,就是所有的采样都是独立同分布的。
最大似然估计是怎么做的呢?个人理解:对于一个概率分布(或离散或连续),抽出一个具有n个值的采样(结果采样),确定一个似然函数:$\operatorname{lik}(\theta)=f_{D}\left(x_{1}, x_{2}, \ldots, x_{n} \mid \theta\right)$,在θ的所有取值上,使这个函数最大化。这个使可能性最大的值即被称为θ的最大似然估计。

